스프링 배치 - 멀티 스레드 처리
대량의 데이터를 처리할 때 배치를 이용하게 될 때 단일 스레드 보다 멀티 스레드를 이용하여 처리하는 방법에 대해 알아보겠습니다.
스레드 개념
단일 스레드 - 프로세스 내 특정 작업을 처리하는 스레드가 하나일 경우 단일 스레드
멀티 스레드 - 여러 개일 경우 멀티 스레드 정의
단, 멀티 스레드 처리 방식은 데이터 동기화 이슈가 존재 하기 떄문에 최대한 고려해서 결정해야 합니다.
스프링 배치 멀티 스레드 프로세싱
Main Thread 부터 시작하면 스프링 배치에서는 반복작업을 수행하기 위해 RepeatTemplate 을 사용하는데 멀티스레드에서는 RepeatTemplate을 상속받은 TaskExecutorRepeatTemplate 통해서 반복을 시킵니다.

TaskExecutorRepeatTemplate 이 반복자로 사용되며 설정한 개수 (ThrottleLimit) 만큼의 스레드를 생성하여 수행하게 됩니다.
TaskExecutor는 스레드를 생성하고 관리합니다.
execute() 가 실행이되고 TheadPool 에서 여러 Thread가 관리됩니다. 이 작업에서 TaskExecutor 는 Runnable 작업을 스레드 풀에 제출하여 병렬로 실행하게 합니다.
TaskExecutor가 execute 할때마다 runnable이 생성되는 구조 입니다.
thread 마다 executingRunnable 클래스가 할당이 되서 각각 실행됩니다. ExecutingRunnable 객체를 생성하고, 이를 TaskExecutor를 통해 비동기적으로 실행합니다.
TaskExecutorRepeatTempalte run() 메소드
ExecutingRunnable 클래스안에 run 메소드가 실행되면 RepeatCallback 메소드가 실행됩니다.
callback.doIntIteration이 executingRunnable 에서 별도의 스레드에 의해 생성된다. 그리고 이 result는 repeatStatus를 가지고 있다. (반복할지, 안할지)
executeRunnable을 queue에 담는다.
작업의 결과는 BlockingQueue를 통해 수집되며, 큐가 비어 있을 경우 결과가 추가될 때까지 기다립니다.

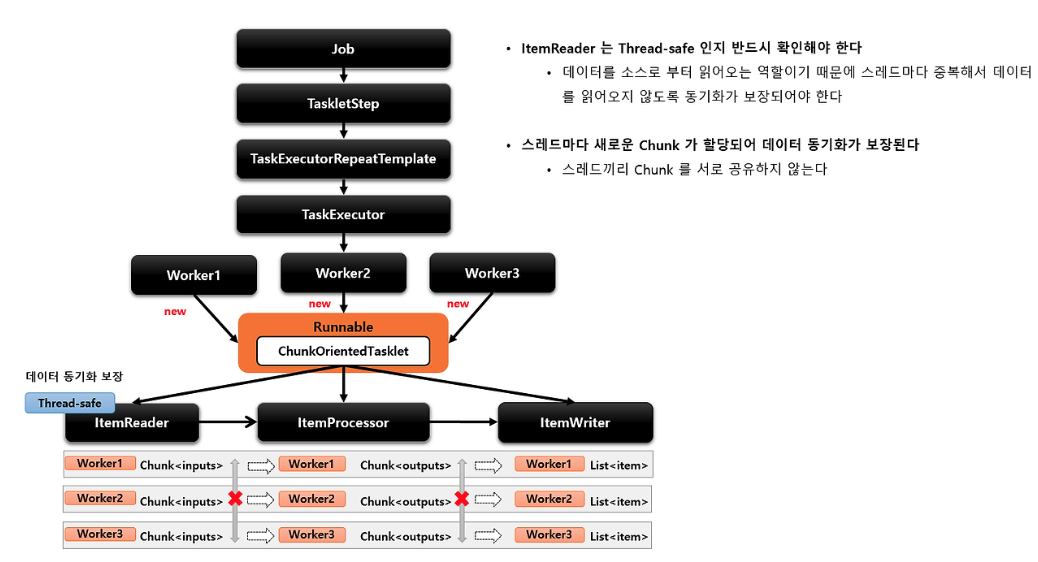
Thread-Safe
Worker1, Woker2, Woker3 은 ChunkOrientedTasklet을 공유합니다.
ItemReader 부분에서 Item을 담는 Chunk는 새롭게 생성됩니다. 그래서 Thread-Safe하게 된다. 같은 데이터를 읽어오지 않도록 Thread-Safe하게 처리가 되어야 합니다.
각각의 스레드는 Stack을 가집니다.
LIFO, 가장 마지막에 담은 데이터를 가장 먼저 가지고 오게되는데, 스프링 배치에서 아이템 리더 실행할때마다 새로운 Chunk 매번 생성됩니다.
각각의 스레드가 그 Chunk값을 가지고 있습니다.
'IT' 카테고리의 다른 글
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 1장 - 사용자 수에 따른 규모 확장성 (2) (0) | 2024.07.21 |
|---|---|
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 1장 - 사용자 수에 따른 규모 확장성 (1) (0) | 2024.07.14 |
| zipkin (2) | 2024.07.01 |
| 스프링 클라우드 슬루스와 집킨 정리 (0) | 2024.06.30 |
| 트랜잭션 (0) | 2024.05.26 |
댓글을 사용할 수 없습니다.