zipkin
들어가기
트위터에서 개발되서 사용하고 있는 분산 추적 도구입니다. 마이크로서비스 환경에서는 하나의 Request 요청에 대해 여러개 서비스들이 호출되곤 합니다. 이때, 데이터를 받아오는 다소 무거운 API가 있으면 Spring 서버의 경우 스레드가 묶여 버리는 일종에 병목 현상의 문제가 발생할 수 있습니다. 이런 경우를 대비하여 모니터링이 필요하게 됩니다.
Zipkin을 통해서 이러한 병목 현상을 대비할 수 있는 모니터링 역할을 수행하게 됩니다.
Twitter 에 공개되어 있는 Distributed Systems Tracing with Zipkin 본문 링크입니다. 조금 오래된 문서이긴 하지만 zipkin 등장이유와 동작방식에 대해 확인해볼 수 있습니다.
Zipkin 이란 무엇인가?
Zipkin은 분산환경에서 로그 트레이싱을 제공해주는 오픈 소스입니다. github에서 관련 내용을 확인해볼 수 있습니다.

Zipkin을 잘 쓰기 위해서는 Spring Cloud Sleuth가 필요합니다.
Spring Cloud Sleuth란?
Zipkin 과 함께 사용되는 Tracer 가 존재합니다.
TraceID, SpanID를 생성해 주는 것이 바로 Spring Cloud Sleuth 입니다.
두 아이디는 사용자 Request 정보에 따라 TraceID 그리고 마이크로 서비스당 아이디를 제공해주는 SpanID가 존재하게 됩니다.
Spring Cloud Sleuth는 Spring에서 공식적으로 지원해주는것이 Zipkin Client Library이며 Spring 연동이 쉬워 많이 사용되고 있는것 같습니다.
아래 그림을 보면 마이크로 서비스 A, B, C 가 존재할 때 TraceID는 클라이언트가 요청을 보낸 시점으로부터 동일한 TraceID를 처리하게 됩니다. 그리고 SpanID의 경우에는 마이크로 서비스당 하나의 ID를 부여하게 되는데요. 이렇게 처리하므로써 사용자가 클라이언트와 마이크로 서비스를 구분할 수 있게 됩니다.

Zipkin 작동원리
Zipkin은 Zipkin Client Library, Zipkin Server 구성됩니다.
Zipkin Server는 크게 4가지로 구성됩니다.
Collector, Storage, API(Query Service), Web UI(Dashboard)로 구성됩니다.
Zipkin Client Library
트레이서에 의해 수집된 정보는 Zipkin Server의 Collector 모듈로 전송됩니다. 지원되는 언어 및 프토콜 확인은 여기서 하실 수 있습니다.
Collector로 전송할 때 여러 프로토콜을 사용할 수 있지만 일반적으로 HTTP 사용하고, 시스템이 클 경우 Kafka 큐를 통해서 전송하기도 합니다.
Collector
Zipkin Client Library로부터 전달된 트레이스 정보 유효성을 검증하고 검색 가능하게 저장 및 색인화를 진행합니다.
Storage
Zipkin Collector로 보내진 트레이스 정보는 Storage에 저장됩니다.
API(Zipkin Query Service)
저장되고 색인화된 트레이스 정보를 검색하기 위한 JSON API 이며, Web UI에서 호출됩니다.
Web UI
수집된 트레이스 정보를 확인할 수 있는 GUI로 구성되어 있는 대쉬보드입니다. 서비스, 시간, 어노테이션 기반으로 데이터 확인이 가능합니다.

zipkin 트레이스 수집 도식화

zipkin 서버에서 일어나고 있는 일
zipkin 시작하기
실행환경은 AWS EC2 기준으로 작성되었습니다.
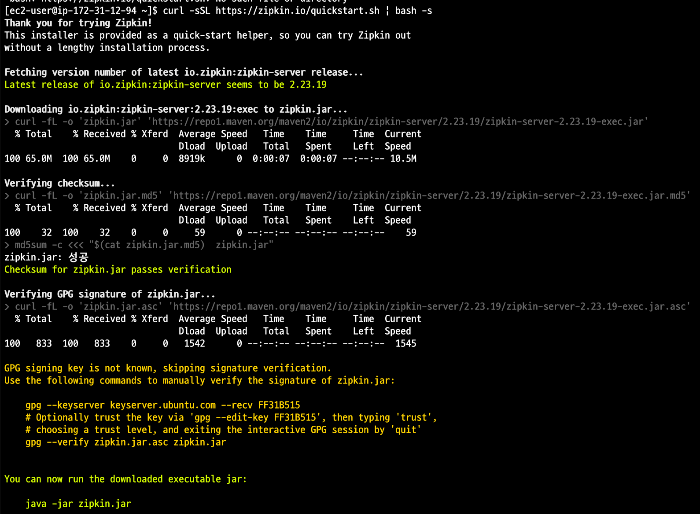

port 9411 open 후 http://{EC2-IP}:9411 로 접속해볼 수 있다.

Spring API Gateway 를 구성해서 MSA 환경을 만들어보고 Zipkin 트레이서에 의해 정보가 수집되는지 확인해본다.
'IT' 카테고리의 다른 글
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 1장 - 사용자 수에 따른 규모 확장성 (1) (0) | 2024.07.14 |
|---|---|
| 스프링 배치 - 멀티 스레드 처리 (0) | 2024.07.07 |
| 스프링 클라우드 슬루스와 집킨 정리 (0) | 2024.06.30 |
| 트랜잭션 (0) | 2024.05.26 |
| resilience 4j 발표 내용 정리 (0) | 2024.04.21 |