몽고디비 인덱스 정리
인덱싱 소개
인덱스를 사용하지 않은 쿼리를 컬렉션 스캔이라고 한다. 인덱스를 선택할때는 자주 사용되는 열을 적용하는것이 효과적이다. 예를들어, 자주 중복되지 않은 ID나 이메일 컬럼에 인덱스를 설정하면 좋다.
인덱스 생성

인덱스가 생성된 후에 아래와 같이 쿼리해보면 executionTimeMillis 가 1s로 쿼리 시간을 단축시켜준다. 하지만, 인덱싱은 필드를 변경하는 쓰기 작업은 오래 걸린다. 데이터가 변경될때 도큐먼트만 아니라 모든 인덱스를 갱신해줘야 하기 때문이다. (인덱스는 필드의 순서값을 유지하기 때문이다.)
복잡한 인덱스 소개
아래 쿼리는 email 로 정렬한 후에 name으로 정렬한다. 우리가 미리 만들어둔 name으로 정렬하는건 크게 도움이 되지 않는다. 정렬을 최적화하기 위해서는 email, name을 같이 복합 인덱스로 만들어야 한다.
그래서 복합 인덱스를 만들려면 아래와 같이 둔다. 내부적으로 보면 각 인덱스 항목은 email과 name 을 포함하고 있는 레코드 식별자를 만든다고 한다. 레코드 식별자는 내부에서 스토리지 엔진에 의해 도큐먼트 데이터를 찾는다.
아래와 같이 find 쿼리를 사용한다고 할때 몽고 디비는 이미 정렬된 email 과 일치하는 항목부터 순서대로 인덱스를 탐색하게 된다.
하지만, 다중값 쿼리를 할때 결과가 32메가바이트 이상이면 몽고DB는 데이터가 더누 많아 정렬을 거부한다는 요청을 보낸다. 복합 인덱스를 구성할 때는 정렬 키를 첫번째로 놓고 사용하면 좋다.
몽고DB가 인덱스를 선택하는 방법
여러 쿼리 플랜이 경쟁한다. 모양이 동일한 후속 쿼리가 있을 때는 몽고DB 서버에서 어떤 인덱스를 선택할 지 알 수 있다. 서버는 쿼리 플랜의 캐시를 유지하기 때문이다. 하지만, mongod 프로세스를 다시 시작할 때 삭제도니다.
복합 인덱스 사용
먼저 복합인덱스를 고려할때 트레이드오프가 필요할 수 있는 정렬이 처리되는 방식을 생각해보자. 테스트셋이 많지 않지만 두 인덱스를 생성했다고 가정해보자.
db.users.createIndex({"name" : 1}) db.users.createIndex({"name" : 1, "email" : 1})
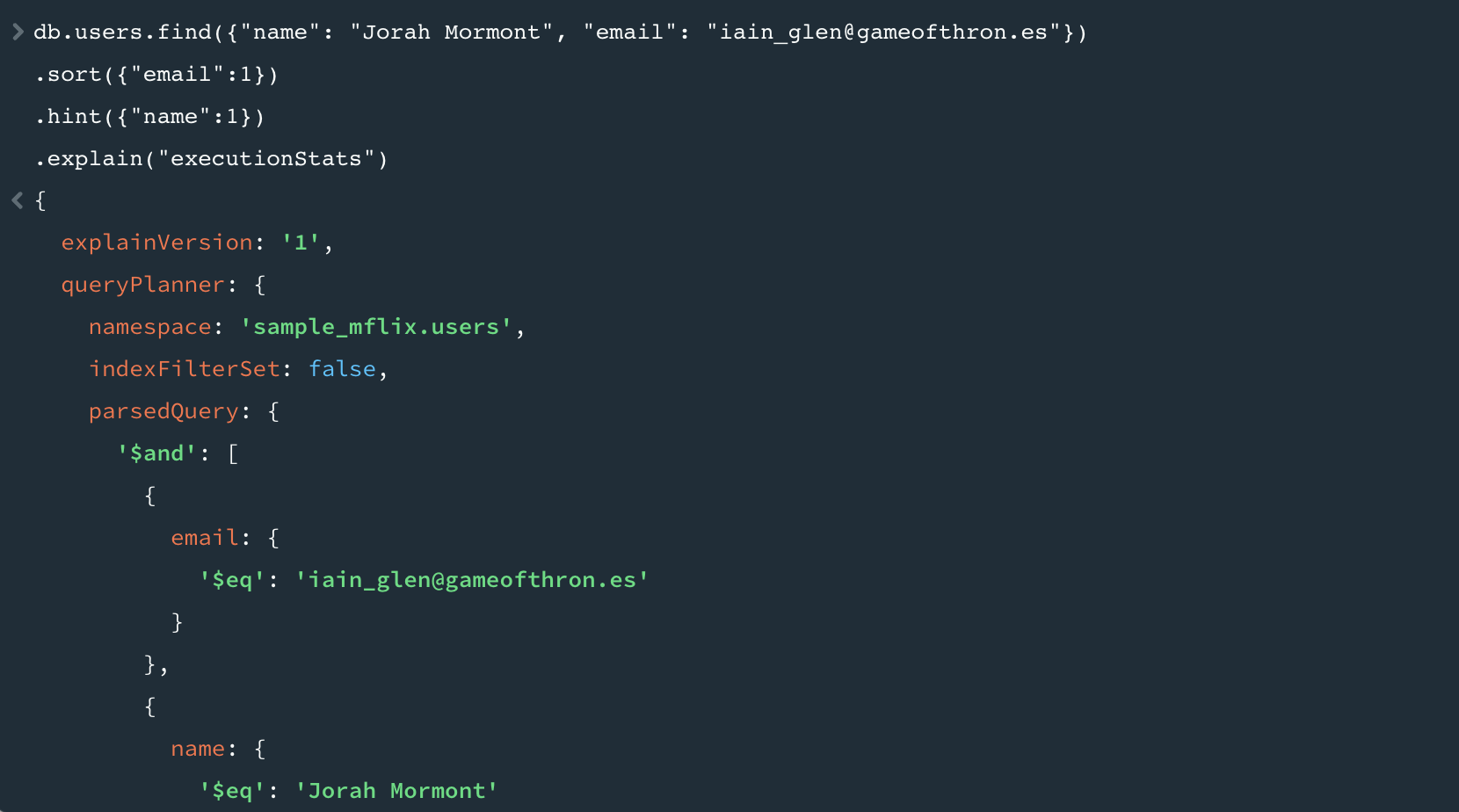
email로 오른차순 정렬하고 name 과 email이 일치하는 데이터를 찾게된다. explain 을 통해서 실행통계를 살펴볼 수 있다. 여기서 몽고DB가 쿼리를 처리하는 방법에 대해 고민해볼 수 있다.
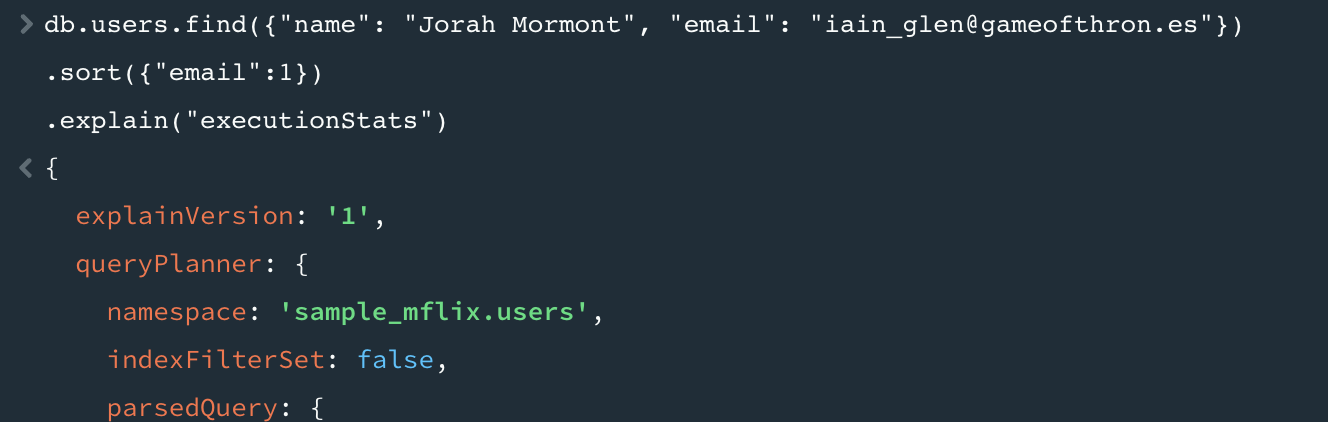
executionStats 필드는 쿼리 플랜에 대해 완료된 쿼리 실행을 설명한다. totalKeysExamined 이 필드는 몽고 DB가 결과 셋을 생성하기 위해 인덱스 내에 몇 개의 키를 통과했는지 나타낸다. 데이터셋이 많지 않아서 일치하는 도큐먼트 1개를 찾기 위해 인덱스 키 1개를 검사했다.
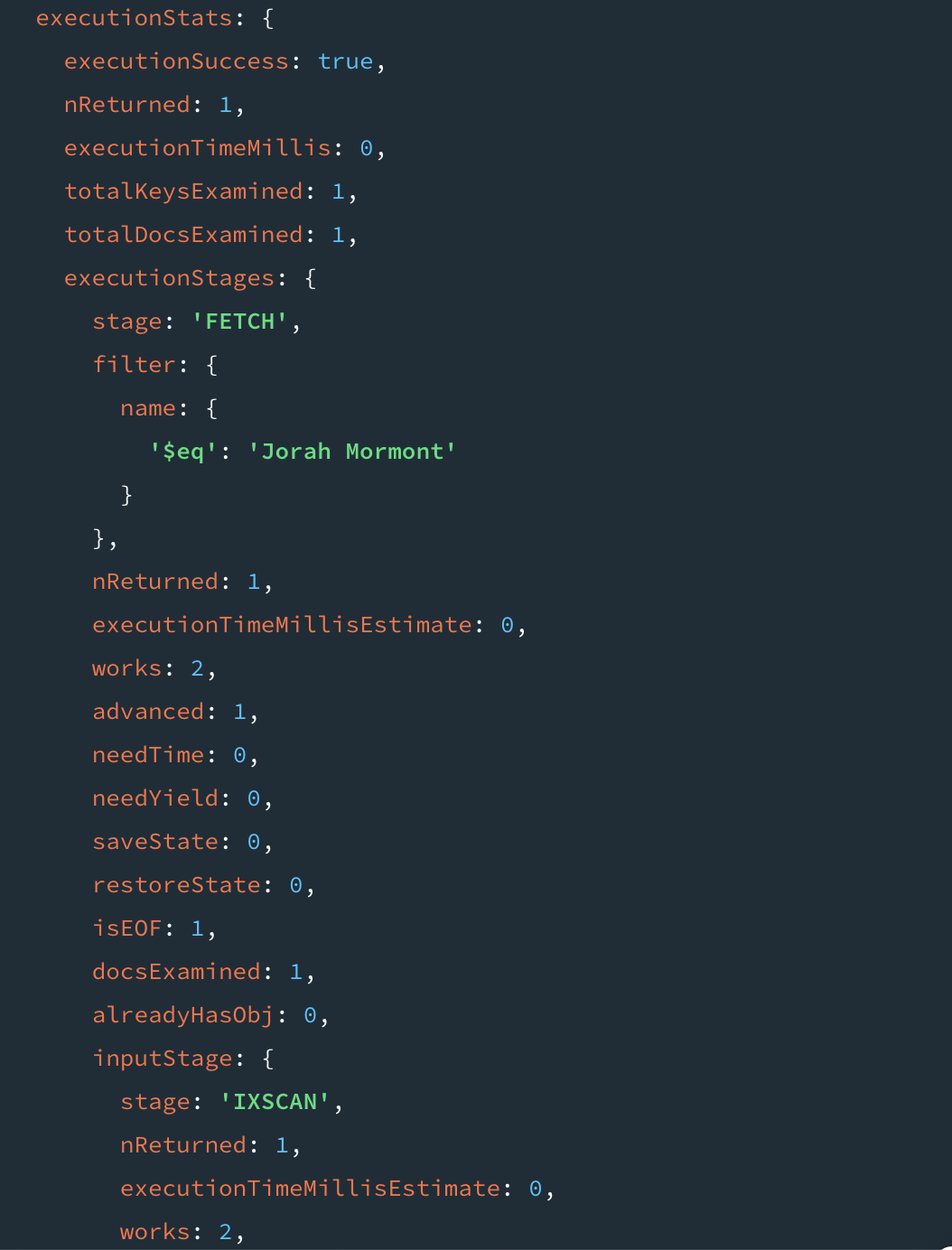
executionTimeMills 는 쿼리가 실행하는데 걸린 시간이다. 거의 뭐 0에 수렴한 값이 나왔다.
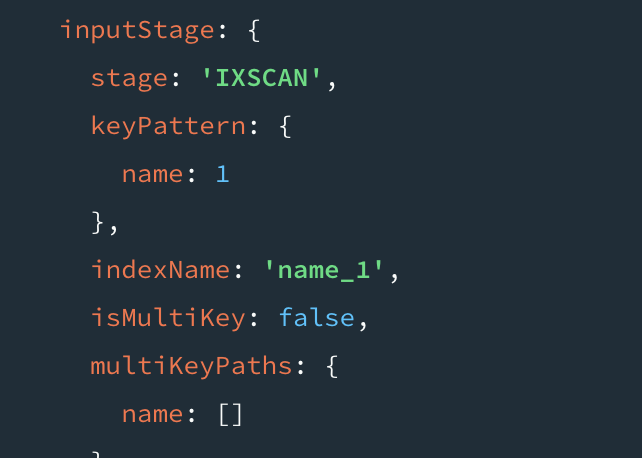
쿼리 플랜은 winningPlan 이 필드를 참조해보면 된다. rejeected 플랜은 안보인다. keyPattern 을 보면 email 키만 가지고 쿼리를 한것을 확인해볼 수 있다.
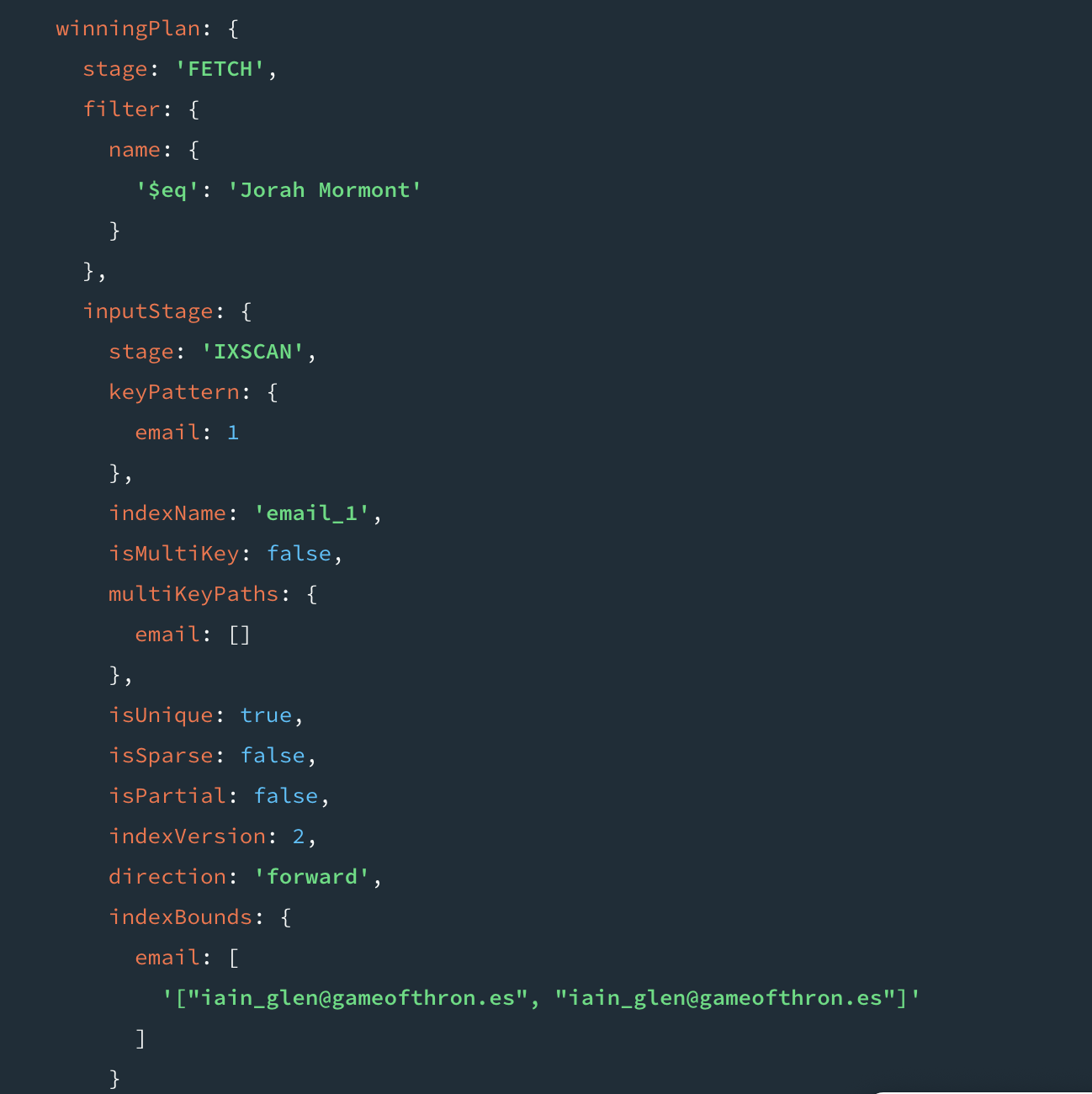
쿼리 시 hint 를 사용하면 사용할 인덱스를 지정할 수 있다. 쿼리 옵티마이저가 인덱스 필터에 지정된 인덱스만 고려하도록 제한 할 수 있다.

범위가 있는게 아니여서 유의미한 차이는 없는거 같다. totalKeysExamined, executionTimeMills 이 크게 차이나지 않아보인다.
find 시 id와 같은 숫자 범위를 입력하고 데이터셋을 늘리면 유의미한 데이터를 확인해볼 수 있을거 같다. hint 를 명시적으로 주면 좀 더 나은 인덱스 설계를 할 수 있다.
또 다른 경우는 복합 인덱스를 순서를 바꿔서 설계하여 explan 으로 쿼리 성능을 체크해보는 것이다. 인덱스를 잘 설계해야 인메모리 정렬을 피할 수 있다.
인덱스 생성 시 정렬에 필요한 인덱스는 앞에 두고 다중값 필터가 있는건 뒤에 둔다.

지금까지 이 챕터에서 나온 내용을 요약하면
- 동등 필터에 대한 키를 맨 앞에 표시한다.
- 정렬에 사용되는 키는 다중값 필드 앞에 표시되어야 한다.
- 다중값 필터에 대한 키는 마지막에 표시되어야 한다.
예)
//인덱스 생성 db.users.createIndex({ age: 1, category: 1 }) //쿼리 db.users.find({ category: { $in: ["A", "B"] } }).sort({ age: 1 })
키 방향 선택하기
인덱스 방향이 중요한데, 일부 필드에 대해 인덱스가 없으면 MongoDB는 인메모리 정렬을 수행하게 된다.
아래 예제를 보면 username이 오름차순으로 설정되어 있어서 정렬 시 MongoDB는 정렬 작업을 최적화하지 못하고 메모리 내에서 정렬을 수행하게 된다.
//데이터 정렬 조건 db.users.find().sort({ age: 1, username: -1 }); //잘못된 복합 인덱스 db.users.createIndex({ age: 1, username: 1 });
복합 인덱스에서 모든 필드의 정렬 방향에 -1을 곱하면 서로 동등하게 사용할 수 있다. MongoDB가 인덱스의 정렬 방향을 뒤집는 역방향 정렬을 최적화하여 지원한다.
커버드 쿼리 사용하기
인덱스는 적합한 도큐먼트를 찾는 데 사용되고, 실제 도큐먼트를 가져오기 위해 포인터를 따라간다. 그런데 MongoDB가 인덱스만으로 쿼리를 처리할 수 있으면 데이터베이스에서 실제 도큐먼트를 조회하지 않아도 된다. MongoDB가 인덱스만 사용하여 쿼리를 처리했음을 의미하는게 IXSCAN단계가 처리되고 executionStats 에서 totalDocsExamined 값이 0이 된다.
*IXSCAN 단계 = Index Scan, 인덱스만으로 쿼리를 처리하는 경우
*FETCH 단계 = 인덱스를 사용해 도큐먼트를 조회하는 단계
*totalDocsExamined = MongoDB가 직접 읽은 도큐먼트의 수를 나타낸다.
암시적 인덱스
복합 인덱스가 특정 조건에 따라 단일 필드 인덱스처럼 동작할 수 있다.
- 전체 복합 인덱스 사용
- 첫 번째 필드만 사용
복합 인덱스는 접두사에 해당하는 필드만 쿼리에 사용될 경우에만 최적화가 이루어진다.
예를 들어서, { a: 1, b: 1, c: 1 }
- {"a": 1} -> 최적화 가능 (접두사 사용)
- {"a": 1, "b": 1} -> 최적화 기능 (접두사 사용)
- {"b": 1} -> 최적화 불가능 (접두사가 아님)
- {"a": 1, "c": 1} -> 최적화 불가능 (순서를 건너뜀)
ref
- 몽고 DB 완벽 가이드
'DataBase' 카테고리의 다른 글
| Mongo : Transaction (0) | 2024.03.24 |
|---|---|
| Database01 :: TOPIC01 (0) | 2018.12.31 |
댓글을 사용할 수 없습니다.