Kafka 개요
시작~

카프카에 대해 알아보겠다. 카프카는 2011년 LinkedIn에서 개발 되었다. 많은 기업들이 엄청난 양의 데이터를 중복 저장하고 처리량(백만/초)이 걸릴 때 데이터에 대한 실시간 스트림 처리를 수행할 수 있다.
카프카와 관련된 특징을 몇가지 소개해보고자 한다.
Apache Kafka는 하루에 수조 개의 이벤트를 처리할 수 있는 분산 스트리밍 플랫폼입니다. Kafka는 짧은 대기 시간, 높은 처리량, 내결함성 게시 및 구독 파이프라인을 제공하고 이벤트 스트림을 처리할 수 있다.
1. Distributed
분산 시스템(Distributed System)은 여러개 컴퓨터로 나누어서 마치 하나처럼 돌리는것을 의미한다. 마치 end-user에게는 클러스터 위에 하나의 node로 표시된다. 카프카는 서로 다른 노드로 메시지를 보내고, 받고 저장하는 과정을 거치게 된다. 이것을 brokers 라고 부른다. 이렇게 카프카가 동작하면서 높은 확장성과 내결함성의 이점을 가지게 된다.
2. Horizontally Scalable
이 용어에 대해 살펴보기 전에 vertical scalability 에 대해 정의해보면 일반적으로 우리가 쓰는 데이터베이스 서버가 존재한다고 했을 때 단순히 서버의 리소스(CPU, RAM, SSD)를 늘리는것을 의미한다. 이것이 vertical scalability 이다. 하지만 vertical scalability의 한계는 하드웨어 의한 한계 그리고 downtime 이 요구된다. (scale up하는데) 특히, 엔터프라이즈의 경우 이러한 시간을 감내하는것은 엄청난 손실로 이어질 것이다.
그래서 Horizontally Scalable 을 통해서 더 많은 머신을 투입하여 관련 문제를 해결하는것이다. 이러한 방식은 새 머신을 추가하는데 가동 중지 시간이 요구되지 않는다. 또, 머신 수 제한도 없다. 하지만, 특정 시스템의 경우에는 Horizontally Scalable 을 지원하지 않을 수 있다. 클러스터 위에서 기본 동작을 수행하기 때문에 클러스터와 호환되지 않는 경우 문제가 생길 수도 있다.
3. Fault-tolerant
분산 시스템이 아닌 경우 SPoF(단일 장애 지점)이 생길 수 있다. 단일 데이터베이스가 실패하면 머신이 아예 동작하지 않게 되서 서비스 자체가 엉망이 된다. 분산 시스템의 경우에 이러한 장애를 대비할 수 있게 설계되어있다. 카프카 클러스터에 노드는 하나의 노드가 다운되더라도 계속 작동합니다. 시스템의 내결함성(Fault-tolerant)이 높을 수록 성능이 떨어지기 때문에 내결함성은 성능과 직접적인 상충 관계가 있다는점에 주목하자
4. Commit log
Commit Log는 transaction log 나 write-ahead log 를 가리킨다. 이러한 Commit Log를 추가하게 되면 영구적으로 순서를 지키는 data structure를 가지게 된다. 여기서 각 record는 삭제하거나 수정할 수 없다. 왼쪽에서 오른쪽으로 읽고 항목 순서를 보장한다. 카프카 구조는 아래처럼 단순한 자료구조를 지내게 된다. 이것이 카프카의 핵심이다. 순서를 제공해준다. 카프카는 모든 메시지를 디스크에 저장하고 아래 구조에서 순서를 지정하게 되면 순차적으로 디스크를 읽어오게 됩니다.
레코드 ID를 알고 있다면 읽기 및 쓰기 시간은 O(1)로 접근할 수 있다. 그리고 읽기와 쓰기는 서로 영향을 미치지 않는다. 이처럼 데이터 크기와 성능 자체가 완전 분리 되어있기 때문에 좋은 성능을 제공할 수 있는 환경이 된다. 예를들어서 카프카는 서버에 100KB 혹은 100TB 데이터 여부 상관없이 동일한 퍼포먼스를 제공한다.
다음은 카프카가 어떻게 동작하는지 살펴보자.
Application(producers) 에서 message(records)를 Kafka node(broker)로 보낸다. 그리고 다른 Application이 존재하게 되면 (consumer) 에서 해당 message가 처리된다. 그리고 message는 카프카 topic에 저장되고 consumer는 topic을 구독하여 새 message를 받게된다. topic이 커지게 되면 성능, 확장성을 고려해 작은 크기의 partition으로 분할된다. 카프카는 partition 내부의 모든 메시지가 들어온 순서대로 정렬되어 보장된다.
특정 메시지를 구별하는 것은 Offset을 통해 이루어진다. Offset은 일반적인 배열 index 처럼 사용된다. Offset은 각각 메시지에 대해 증가하는 sequence id 번호가 된다.
카프카는 dumk broker and smart consumer 원리를 따르게 된다. 카프카는 소비자가 읽은 record에 대해 추적한 후에 삭제하지 않는다. 일정 시간 동안 일부 크기 임계값이 충족될때까지 저장한다. 소비자들은 새 메시지에 대해 카프카를 polling 방식으로 record를 읽어온다. polling 으로 record를 읽어올 때 offset의 증가, 감소 시키면서 event 생성, 처리하게 된다.
consumer는 실제로 내부를 보게 되면 consumer group 이라는 점을 착안할 수 있다. 동일한 메시지를 두 번 읽는것을 방지하기 위해 각 카프카 topic 의 partition된 그룹당 하나의 consumer 프로세스에 연결된다.
5. Persistence to Disk
카프카는 모든 record를 디스크에 저장하고 ram에는 아무것도 저장하지 않는다. 카프카에는 메시지를 그룹화하는 프로토콜이 있다. 메시지를 그룹화하여 네트워크 오버헤드를 줄여준다. 서버는 많은 메시지 청크를 유지하고 소비자는 큰 선형 청크를 한 번에 가져온다.
디스크의 선형 읽기/쓰기 속도는 빠르다. 선형 작업은 read-ahead(prefetch large block multiples) 와 write-behind(group small logical writes into big physical writes) 기술을 통해서 OS에 최적화되어 있다. 최신 OS에서는 페이지 캐시 작업을 하는데 디스크를 여유 ram에 캐시하기도 한다. 카프카는 전체 흐름(생산자 - 브로커 - 소비자) 걸쳐 표준화된 바이너리 형식으로 메시지를 저장하기 때문에 zero-copy 최적화를 수행한다. OS가 페이지 캐시에서 소켓으로 직접 데이터를 복사하는 경우이다. 카프카 브로커 애플리케이션을 우회하게 된다.
*zero-copy : CPU와 GPU 간의 병렬 처리를 통해 웹 콘텐츠를 보다 빠르게 렌더링하기 위한 방법으로, 특히 이미지나 플래시 등을 로딩할 경우 시스템 메모리에 올린 뒤 VGA 카드의 VRAM으로 복사하는 과정을 생략함으로 속도 향상 및 메모리 누수를 방지하는 효과
6. Data Distribution and Replication
Partition 데이터는 브로커가 장애가 일어날 경우 데이터를 보존하기 위해 여러 브로커로 복제된다. Partition Reader는 하나의 브로커가 partition을 소유하고 애플리케이션이 partition에서 읽고 쓰게 된다. followers n개의 다른 브로커에게 복제한다. followers에 데이터를 저장하고 reader node가 죽을 경우 reader의 대기열에 속하게 된다. 생산자/소비자가 partition에 read/write 하려면 reader를 알아야 하는데 Zookeeper 라는 서비스에 저장한다.
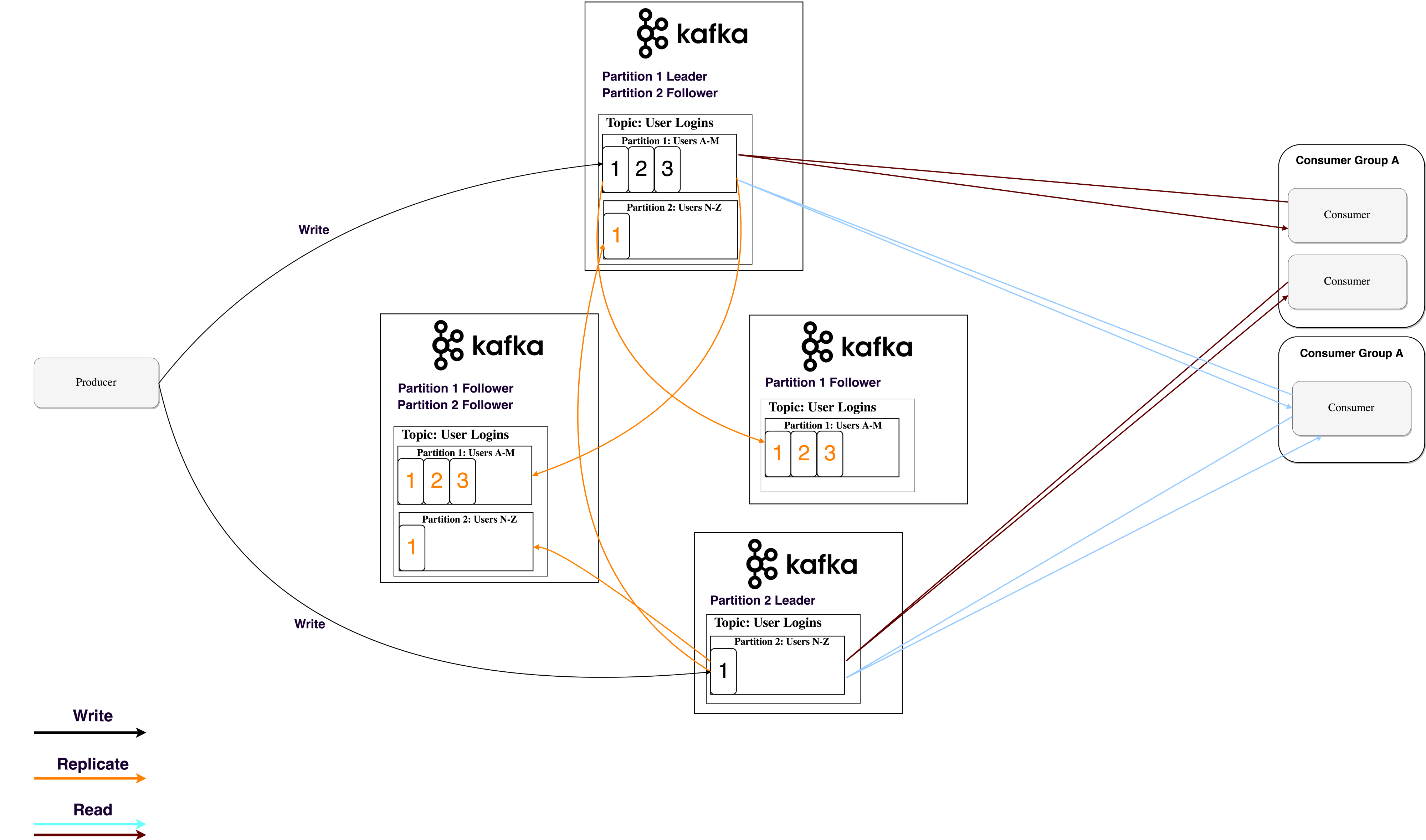
6. Zookeeper
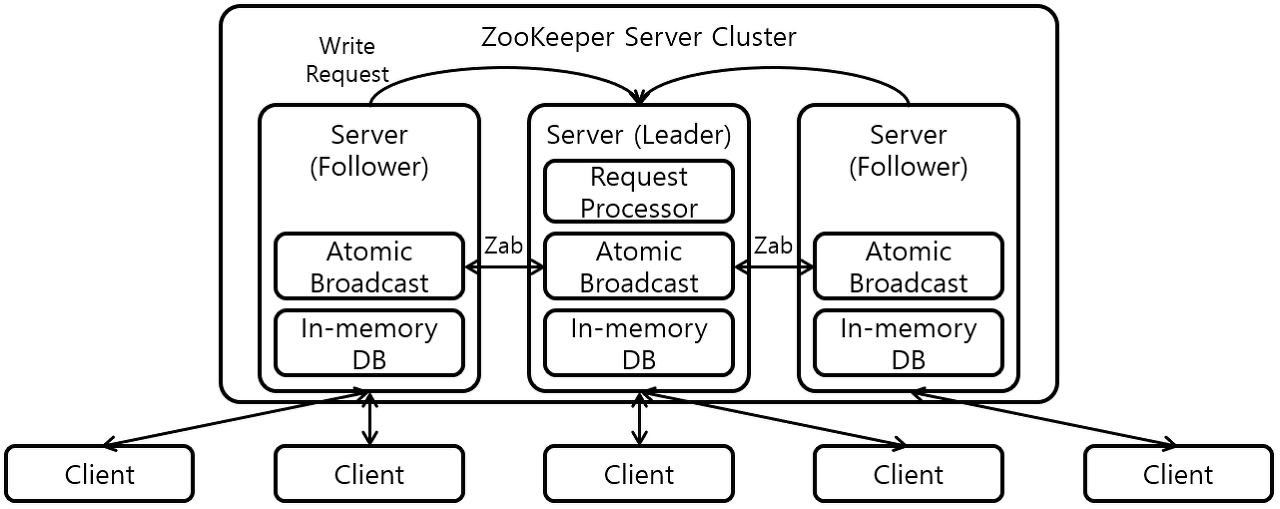
Zookeeper는 distributed key-value 저장소 이다. 읽기에 최적화되어 있고, 쓰기는 느리다. 메타데이터를 저장하고 heartbeats, distributing updates/configurations 과 같은 클러스터링 메커니즘을 처리하는데 사용된다. 서비스 클라이언트(Kafka 브로커)가 구독하고 변경 사항이 발생하면 변경사항을 보낼 수 있다. 이 시기 즘에 브로커가 partition reader 가 될 수 있는지, 아닌 지 알 수 있게 된다. Zookeeper 가 매우 내결함성이 있으며 kafka와 함께 사용된다.
*Zookeeper는 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구이다. API를 이용해 동기화나 마스터 선출 등의 작업을 쉽게 구현할 수 있게 해준다.
그래서 Zookeeper는 partition 당 Consumer groups의 offset을 지정한다. 최근에 client는 각각의 Kafka topic에 offset을 저장한다. Access control lists(ACLs) 이 존재해서 유저의 접근/인증을 제한한다. 그리고 생산자 소비자 모델로 처리할 수 있는 초당 최대 메시지가 존재한다. partition leader를 관리한다.
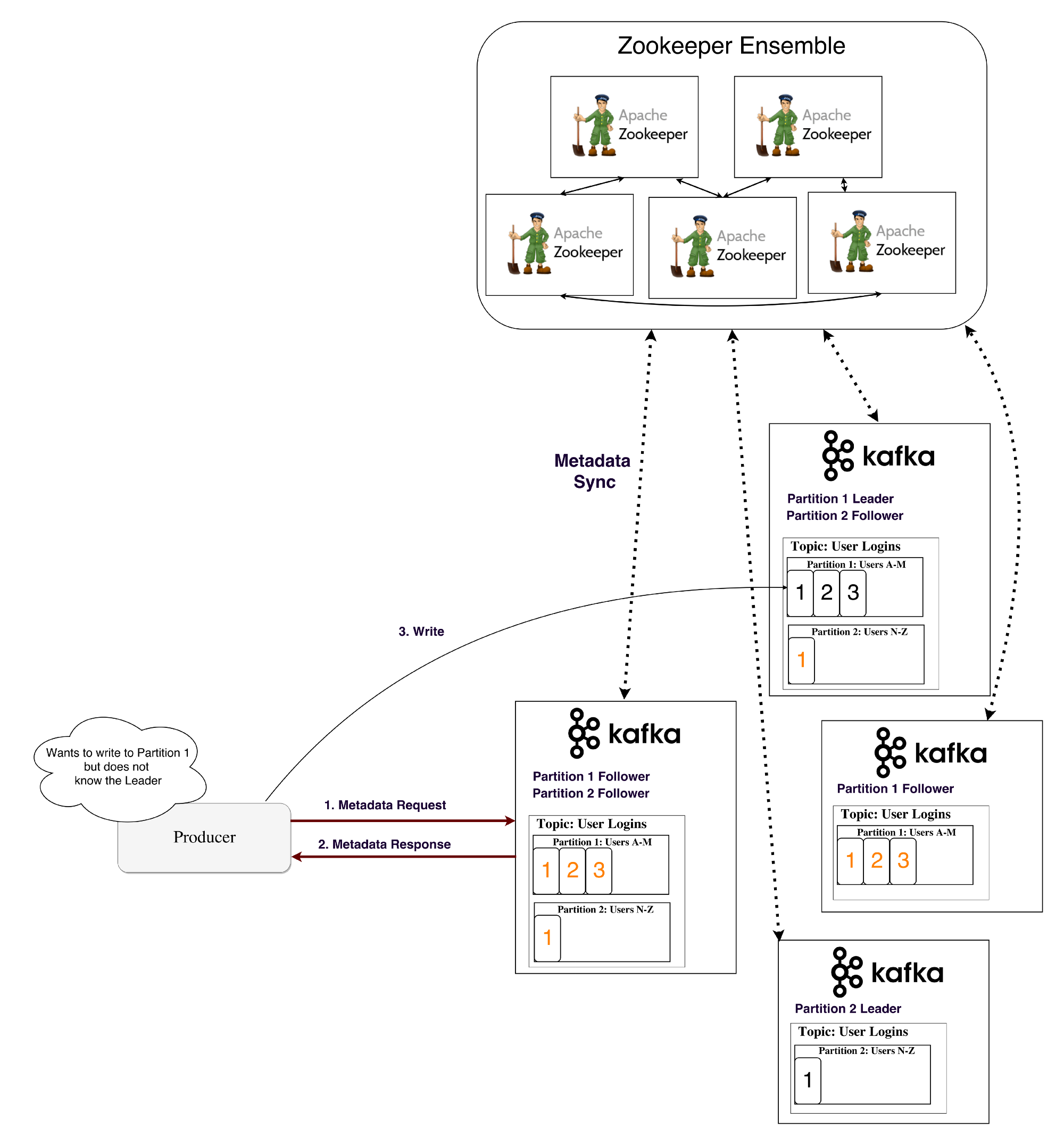
생산자와 소비자는 Zookeeper에 직접 연결해 정보를 얻는다. 그치만 이러한 방식은 결합도 측면에서 좋은 모델이라고 할 수 없다. 카프카 버전 0.8/0.9 부터 클라이언트는 Zookeeper로부터 카프카 브로커로부터 메타정보를 가지고 온다.
7. 스트리밍
카프카에서 스트림 프로세서는 input topic으로부터 지속적으로 들어오는 스트리밍 데이터를 처리한다. 그리고 처리된 스트림 데이터를 output topic으로 보낸다. (output은 service, database 과 같은곳이 될 수 있다.) producer, consumer API를 사용하여 구현된다. 그러나 더 복잡한 transform 을 위해서 카프카는 통합 Streams API 라이브러리를 제공한다.
스트림의 상태 비저장처리는 외부 저장소에 의존하지 않는다. 스트림은 연속적인 데이터 업데이트 과정이라고 볼 수 있다. 그리고 테이블은 스트림의 최종 집계 이다. 이러한 흐름을 event sourcing이라고 부른다. 카프카 스트림은 누적될 때 최종 상태를 형상하는 이벤트 방식으로 이러한 스트림 집계는 로컬 RocksDB에 저장되며 KTable 이라고 한다. (*스트림과 테이블은 동일하다.)
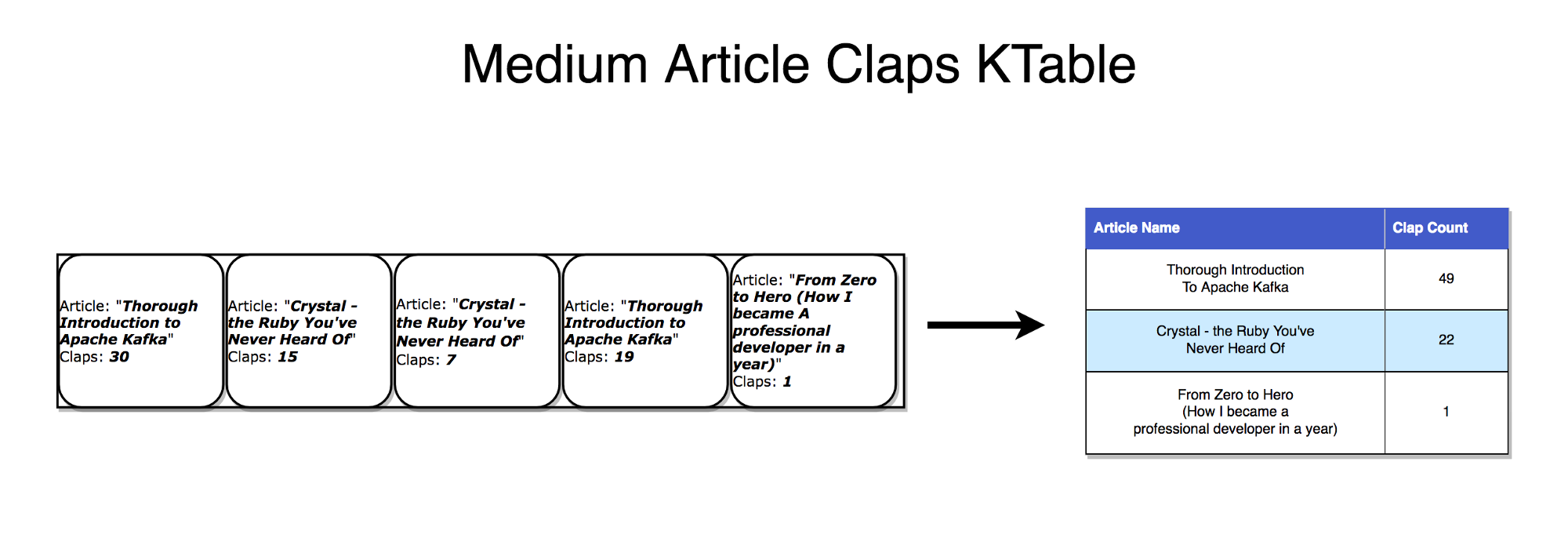
테이블은 스트림에 대해 각 키에 대한 최신 값의 스냅샷을 볼 수 있다. 스트림 레코드가 테이블을 생성할 수 있는 것과 같은 방식으로 테이블 업데이트는 변경 로그 스트림을 생성할 수 있다.
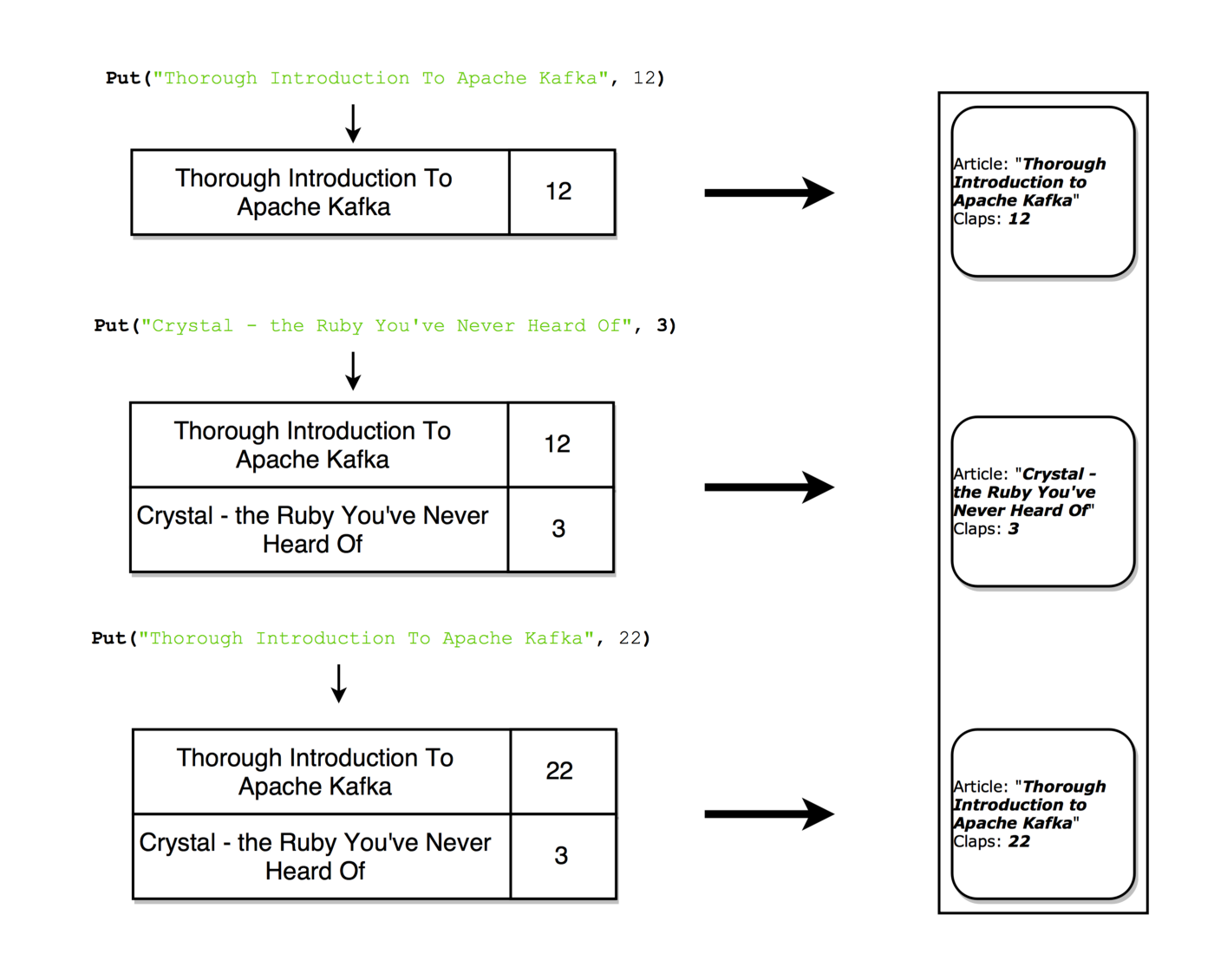
상태 저장 정보는 map() 과 같은 간단한 작업은 상태 비저장을 하게 되지만,

그러나 대부분의 작업은 상태 저장을 하게 되므로 현재의 값을 누적해야 한다. 카프카 브로커에 스트림을 저장하여 내결함성을 처리하는 메커니즘을 제공한다. 스트림 프로세서는 입력 스트림에서 얻는 데이터를 RocksDB와 같은 로컬 테이블에 업데이트 한다. 프로세스가 실패하면 스트림을 다시 확인하게 된다.
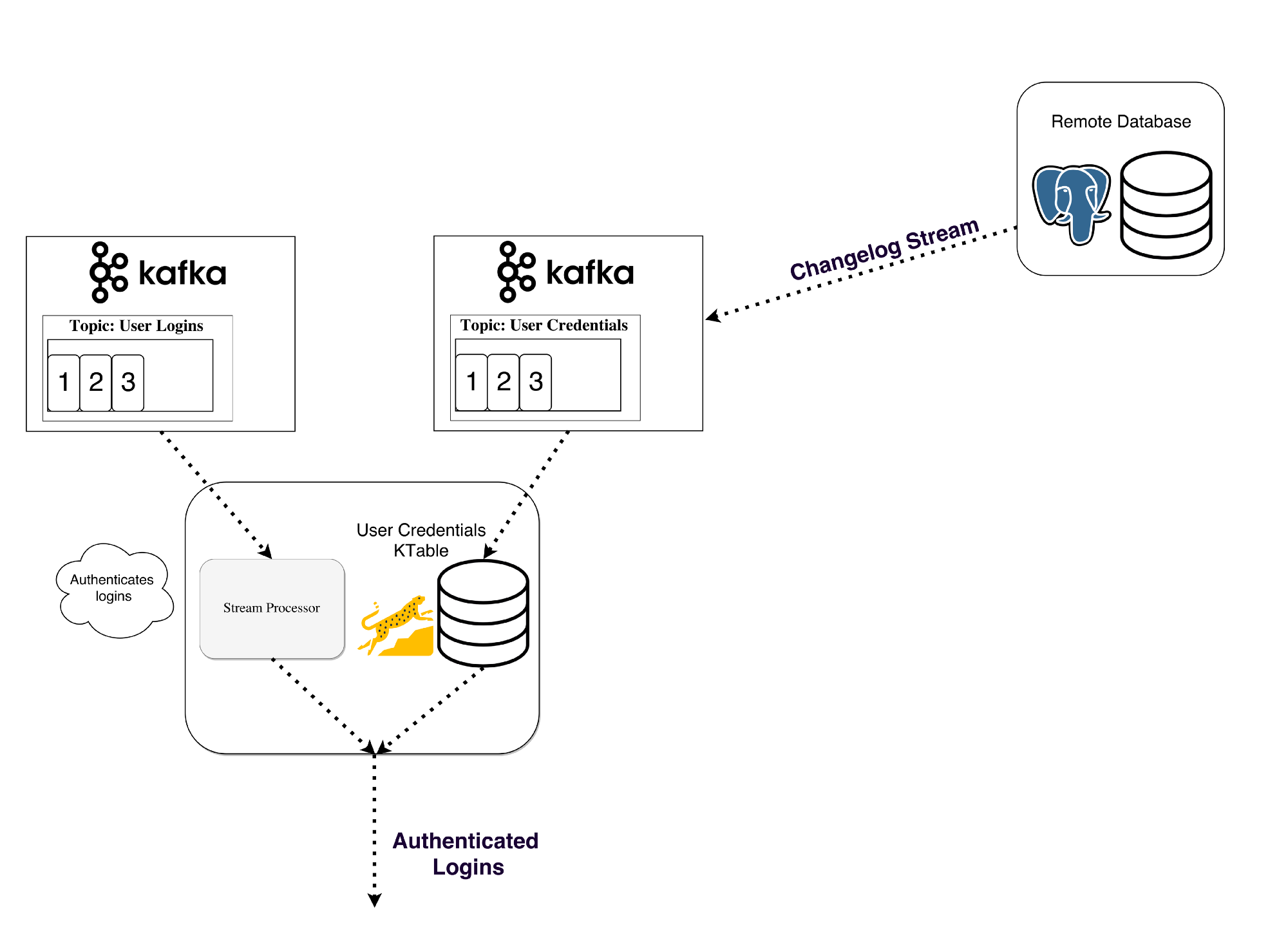
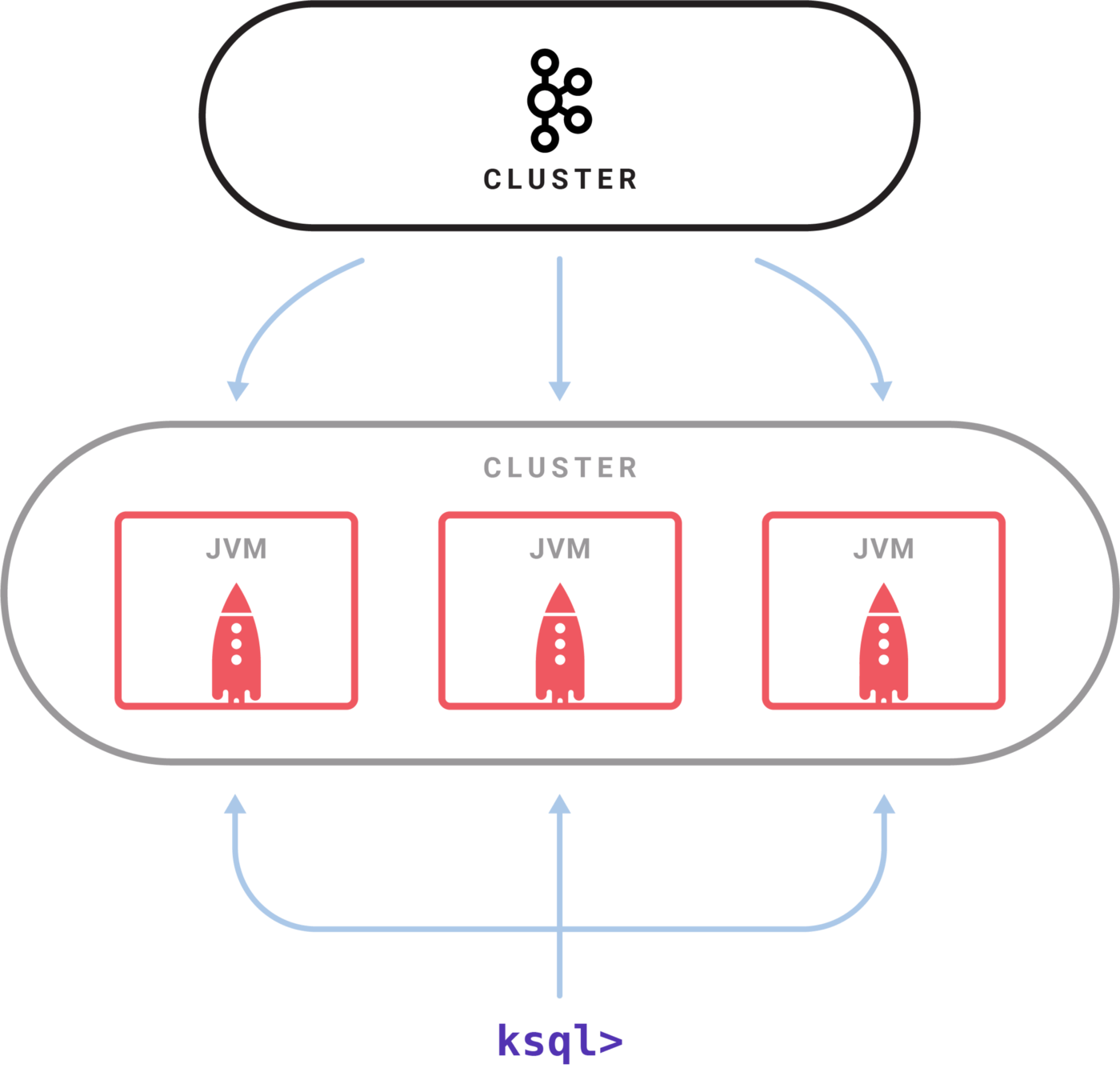
KSQL은 JVM언어로 카프카 스트림 API를 활용해 스트림 처리를 하게 된다. KSQL 서버를 설치하고 CLI를 통한 대화형 쿼리로 처리한다. Kafka Streams를 사용하면 Kubernetes , Mesos , Nomad , Docker Swarm 등 필요할 때 자체 배포 전략을 실행할 수 있다.
Kafka를 사용하면 엄청난 양의 메시지가 중앙 집중식 매체를 거치게 하고 성능이나 데이터 손실과 같은 문제에 대해 걱정하지 않고 저장할 수 있다. 이는 다른 애플리케이션을 연결하는 중앙 집중식 매체 역할을 하는 시스템 아키텍처의 핵심으로 사용하기에 완벽하다는 것을 의미합니다. Kafka는 이벤트 중심 아키텍처의 핵심이 될 수 있다. Kafka를 사용하면 서로 다른 (마이크로) 서비스 간의 통신을 쉽게 분리할 수 있다. Streams API를 사용하면 서비스 소비를 위해 Kafka 주제 데이터를 강화하는 비즈니스 로직을 작성하는 것이 그 어느 때보다 쉬워졌다.

참고 :
https://betterprogramming.pub/thorough-introduction-to-apache-kafka-6fbf2989bbc1
A Thorough Introduction to Apache Kafka
A deep dive into a system that serves as the heart of many companies’ architecture
betterprogramming.pub
https://data-engineer-tech.tistory.com/4
[🧙Kafka] 카프카 정리 - 주키퍼(ZooKeeper)란?
주키퍼(ZooKeeper)란? 분산 코디네이션 서비스를 제공하는 오픈소스 프로젝트 주키퍼는 직접 애플리케이션 작업을 조율하지 않고 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구이다. API를
data-engineer-tech.tistory.com
'카프카' 카테고리의 다른 글
| 카프카 주요 요소 (0) | 2024.09.16 |
|---|---|
| Kafka 시작하기 (0) | 2021.11.19 |
| 카프카01 :: 아파치 카프카 개요 (0) | 2020.08.12 |
댓글을 사용할 수 없습니다.