대규모 시스템 설계 기초 - 4장
오랜만에 책을 펼쳐보았는데 4장 부터 시작한다 1-3장은 내용은 좀 노멀한거 같아서 스킾..
4장은 처리율 제한 장치의 설계이다.
처리율 시스템, 네트워크에서 얼만큼 처리할지 그 양을 의미한다. 그러니까 얼만큼 성능 좋은 시스템을 만들껏이냐의 얘기가 되겠다..

책에서는 클라이언트가 보내는 트래픽의 처리율 (rate) 제어하기 위한 장치로 소개되어 있다.
예시를 하나 들어주는데
- 사용자는 초당 2회 이상 새 글을 올릴 수 없다.
- 같은 ip주소로 하루에 10개 이상 계정 생성 금지
- 같은 디바이스로 주 5회 이상 리워드 요청 금지
이런 제한으롤 처리율 제한 장치를 설계한다.
처리율 제한 장치를 설계할 때 이렇게 제한을 두는 까닭은 몇 가지 장점이 있는듯 하다.
- Dos 방지 - limit이 없다면 API Call이 엄청나게 큐에 쌓일거니 이건 이거대로 문제.. 그래서 Dos를 예방할 수 있다.
- 비용 절감 - 우선순위가 높은 API에 자원할당 가능, 3rd-party 를 쓰는 API는 보통 과금이 되기 때문에 limit을 걸면 어느정도 금액에서 지출 되는 비용을 줄일 수 있다.
- 서버 과부하 방지 - 당연하다.
그럼 이 처리율 장치를 어떻게 만들어 볼껀가?
대략적인 요구사항을 세워야 한다.
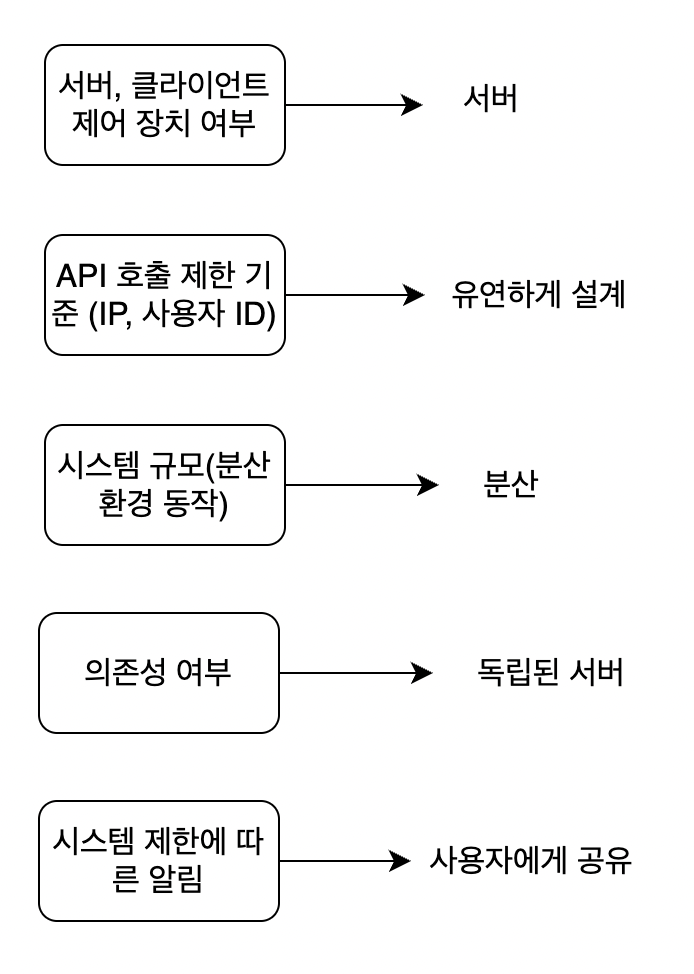
요구사항을 정리하면 개략적으로 설계안에 대해 직관적으로 만드는것이 중요하다.
여기서는 API gateway 를 쓴다고 가정하자 외부로 나가는 API임을 감안한다면 External Gateway를 사용해야 할것 같다.
뭐 여기서는 사용자 인증, IP 허용 목록등을 관리하는 fully managed 방식이라고 한다.
이렇게 처리율을 어디에 둘지 결정했다면 처리율 제한 알고리즘은 어떻게 설계할 것인가?
여러가지가 있다고 한다.
토큰 버킷 (token bucket)
많이 쓴다고 한다. aws에서도 쓴다고 하네요 .. 신기

토큰 안에 사전 설정된 양의 토큰이 주기적으로 채워지고 꽉차면 안채워진다. 그리고 특정 주기 시간으로 토큰이 추가된다. 이건 토큰 공급기 (refiller) 에 의해 추가 되고 버려지는건 overflow 된다고 하네요.
이대로 API 요청 제한에 적용해보자.
클라우드 서비스가 API를 제공해주는데 과도한 요청이 오면 안되잖아.. 그렇게 되면 사용자 별로 토큰 버킷을 설정한다. 사용자당 초당 10개의 토큰을 생성하고, API 요청 하나당 하나의 토큰이 필요하도록 설정한다. 그럼 당연하게도 초당 10개의 API를 보낼 수 있다.
Java
public class TokenBucket {
private long capacity;
private long tokens;
private long lastRefillTimestamp;
private long refillCountPerSecond;
public TokenBucket(long tokens, long refillCountPerSecond) {
this.capacity = tokens;
this.tokens = tokens;
this.refillCountPerSecond = refillCountPerSecond;
this.lastRefillTimestamp = System.currentTimeMillis();
}
public synchronized boolean tryConsume() {
refill();
if (tokens > 0) {
tokens--;
return true;
}
return false;
}
private void refill() {
long now = System.currentTimeMillis();
//refillCountPerSecond 마다 토큰이 채워진다.
long tokensToAdd = (now - lastRefillTimestamp) / 1000 * refillCountPerSecond;
if (tokensToAdd > 0) {
tokens = Math.min(capacity, tokens + tokensToAdd);
lastRefillTimestamp = now;
}
}
public static void main(String[] args) throws InterruptedException {
TokenBucket bucket = new TokenBucket(5, 1); // 1초마다 5개 토큰이 생성된다.
for (int i = 0; i < 10; i++) {
if (bucket.tryConsume()) {
System.out.println("허용된 요청 수 " + (i + 1));
} else {
System.out.println("실패 요청 수 " + (i + 1));
}
Thread.sleep(200); //200ms 마다 보낸다고 가정
}
}
}tryConsume 에서 synchronized 가 붙은 이유는 멀티 스레드를 고려해야 한다. 생각해보면 토큰 수는 원자성을 보장받아야 한다.
이 방식 단점은 버킷 크기랑 토큰 공급률 두개만 가지고 적절한 튜닝을 하는것잉 쉽지 않다.
누출 버킷 (leaky bucket)
토큰 버킷 알고리즘이랑 비슷한데 요청 처리율이 고정되어 있다. 잘 모르겠지만 FIFO 큐로 구현한다고 한다.
고정 윈도우 카운터 (fixed window counter)
윈도우 알고리즘 용어는 데이터를 일정한 window에 분할하여 그 구간내에서 데이터를 처리하는 방식을 의미한다. 아무래도 고정 윈도우 알고리즘이다 보니까 특정 시간대에 발생하는 이벤트를 처리하고 다음 시간대의 이벤트를 처리하는 식으로 진행이 된다.
책에서도 소개한 대로 카운터 값이 (이벤트 수가) threshold에 도달하면 새로운 요청은 새 윈도우가 열릴 때까지 버려지게 된다.
그게 requests < maxRequests 이 부분이다.
Java
import java.util.HashMap;
import java.util.Map;
public class FixedWindowCounter {
private final Map<Long, Integer> requestCounts = new HashMap<>();
private final int maxRequests;
private final long windowSizeInMillis;
public FixedWindowCounter(int maxRequests, long windowSizeInMillis) {
this.maxRequests = maxRequests;
this.windowSizeInMillis = windowSizeInMillis;
}
public synchronized boolean allowRequest() {
long currentTimeMillis = System.currentTimeMillis();
long windowKey = currentTimeMillis / windowSizeInMillis;
requestCounts.putIfAbsent(windowKey, 0);
int requests = requestCounts.get(windowKey);
if (requests < maxRequests) {
requestCounts.put(windowKey, requests + 1);
return true;
} else {
return false;
}
}
public static void main(String[] args) {
// 예제: 1시간(3600000 밀리초) 윈도우에 100개의 요청 제한
FixedWindowCounter counter = new FixedWindowCounter(100, 3600000);
// 요청 테스트
for (int i = 0; i < 120; i++) {
if (counter.allowRequest()) {
System.out.println("요청 #" + (i + 1) + ": 허용됨");
} else {
System.out.println("요청 #" + (i + 1) + ": 거부됨");
}
}
}
}윈도우 자체가 고정되다 보니 그 때 만큼의 이벤트 수를 관리하게 된다. limit가 걸려있어서 메모리 관리에 효율적이다.
이전처럼 객체에 값을 저장하고 있는게 아니라 단순히 카운트만 하기 때문에 이것도 장점이다.
윈도우 종료되고 시작할때 메모리 해제 생성을 할 수 있다. 그러면 당연히 사용하지 않은 메모리는 줄어들겠지..? (GC옵션에 따라 다를듯)
그런데 생각해보면 경계부근에서는 어떻게 처리? -> 못한다.. 그래서 경계 부근에서는 많은 트래픽이 몰려들면 처리가 어려우니 다 빵꾸가 날듯 싶다..
이동 윈도우 로그 (sliding window log)
그래서 나온게 이동형 sliding 이다. 이전에는 window가 고정되어 있었다면 이번에는 window를 이동시킨다. 즉, 시간이나 데이터의 순서에 따라 slide 하면서 새로운 데이터를 포함하거나 오래된 데이터는 제외하는 식으로 구성된다.
책의 말을 인용하면 타임스탬프(*redis에 저장된) 새 요청이 오면 만료된 타임스탬프는 제거하고 새 요청 타임스탭프 를 추가한다. (단, 타임스탬프 로그 크기가 허용치보다 크거나 작거나 시스템에 제한 범위안에서 적용된다.)
자바로 구현하면 아래와 같다.
import java.util.LinkedList;
import java.util.Queue;
public class SlidingWindowLog {
private final Queue<Long> logQueue;
private final long windowSizeInMillis;
public SlidingWindowLog(long windowSizeInMillis) {
this.logQueue = new LinkedList<>();
this.windowSizeInMillis = windowSizeInMillis;
}
public void recordEvent() {
long currentTime = System.currentTimeMillis();
logQueue.add(currentTime);
removeOldEvents(currentTime);
}
private void removeOldEvents(long currentTime) {
while (!logQueue.isEmpty() && (currentTime - logQueue.peek() > windowSizeInMillis)) {
logQueue.poll();
}
}
public int getEventCount() {
return logQueue.size();
}
public static void main(String[] args) throws InterruptedException {
// 예제: 1분 동안의 로그를 유지하는 슬라이딩 윈도우 로그
SlidingWindowLog log = new SlidingWindowLog(60000); // 60,000 밀리초 = 1분
// 로그 이벤트 테스트
log.recordEvent();
Thread.sleep(1000); // 1초 대기
log.recordEvent();
Thread.sleep(50000); // 50초 대기
log.recordEvent();
System.out.println("현재 이벤트 수: " + log.getEventCount());
}
}다만, 이전 타임스탬픙에 대한 로그도 저장하기 때문에 메모리를 많이 잡아 먹는다.
이동 원도우 카운터 (sliding window counter)
이동 윈도우 카운터는 sliding window counter는 고정 윈도우 카운터 알고리즘 + 이동 윈도우 로깅 알고리즘을 합친것이다.
그냥 이동하면서 카운트를 세겠다 정도로 이해하면 될듯 싶다.
고정된 시간 간격으로 이동한다. 1분, 5분 윈도우에 새로운 이벤트가 발생하면 카운터가 증가되고 윈도우가 이동하면서 오래된 이벤트는 제외된다.

그런데 책에서 좀 재밌는 내용이 있어 발췌했다.
처리율 제한 장치의 한도가 분당 7개 요청이 들어온다. 이전 1분 동안에는 5개 요청이 현재 1분 동안에는 3개 요청이 왔다면 현재 1분의 30% 겹친다고 하면 새 요청의 경우 현재 윈도에 몇 개의 요청이 온것으로 처리가 될까?
-> 현재 1분간 요청 수 + 직전 1분간 요청 수 * 이동 윈도 직전 1분이 겹치는 비율
대략 6.5 개
import java.util.LinkedList;
import java.util.Queue;
public class SlidingWindowCounter {
private final Queue<Long> eventTimestamps;
private final long windowSizeInMillis;
public SlidingWindowCounter(long windowSizeInMillis) {
this.eventTimestamps = new LinkedList<>();
this.windowSizeInMillis = windowSizeInMillis;
}
public void recordEvent() {
long currentTime = System.currentTimeMillis();
eventTimestamps.add(currentTime);
removeOldEvents(currentTime);
}
private void removeOldEvents(long currentTime) {
while (!eventTimestamps.isEmpty() && currentTime - eventTimestamps.peek() > windowSizeInMillis) {
eventTimestamps.poll();
}
}
public int getEventCount() {
return eventTimestamps.size();
}
public static void main(String[] args) throws InterruptedException {
// 예제: 1분 동안의 이벤트를 카운트하는 슬라이딩 윈도우 카운터
SlidingWindowCounter counter = new SlidingWindowCounter(60000); // 60,000 밀리초 = 1분
// 이벤트 테스트
counter.recordEvent(); // 첫 번째 이벤트
Thread.sleep(1000); // 1초 대기
counter.recordEvent(); // 두 번째 이벤트
Thread.sleep(50000); // 50초 대기
counter.recordEvent(); // 세 번째 이벤트
System.out.println("현재 이벤트 수: " + counter.getEventCount());
}
}다만 이것도 매우 높은 빈도의 이벤트(API call)이 발생할 경우 큐는 상당한 메모리 낭비를 겪을 수 밖에 없다.
처리율 제한이라면 api call이 몇번 call 되었는지 어딘가에는 저장을 할 필요가 있는데 그게 db에 저장하게 되면 하드디스크에 직접 접근하는것이 되어서 성능을 고려할수는 없을 것같다.
redis 캐시에 저장한다고 한다.
redis 에 다음 명령어로 처리율 카운트를 셀 수 있다.
- INCR : 메모리에 저장된 카운터의 값을 1만큼 증가
- EXPIRE : 카운터에 타임아웃 값을 설정, 설정된 시간이 지나면 카운터 자동 삭제

여기까지가 대략적인 설계라고 한다.
상세 설계 파트
처리율 제한 규칙은 Lyft 를 쓴다고 하는데 자세히 잘 모르겠다.
처리율 제한이 Max를 초과했을 때에는 클라이언트 입장에서는 Too Many Request 429 응답을 받게 된다. 그런데 경우에 따라서 메시지를 나중에 처리하기 위해 큐에 보관할 수 있다.
이럴 때 HTTP 응답 헤더를 클라이언트에 보내게 되는데
X-Ratelimit-Remaining : 윈도우 내에 남은 처리 가능 요청 수
X-Ratelimit-Limit : 윈도우 마다 클라이언트가 전송할 수 있는 전송 수
X-Ratelimit-Retry-After : 한도 제한이 걸리지 않으려면 몇 초 뒤에 요청을 다시 보내야 하는지 알림
이 정보랑 429 응답을 같이 보낸다고 한다.
구체적인 설계
아래 그림에 대한 프로세스를 그려보면 다음과 같다.
1. 작업 프로세스 - 캐시된 규칙 처리율 제한 규칙을 저장한다.
2. 클라이언트 요청에 처리율 제한 미들웨어에서 받게 된다.
3. 처리율 제한 미들웨어는 제한 규칙을 캐시에서 꺼내온다.
- 처리율 제한에 걸리지 않으면 API 서버로 보낸다.
- 제한이 걸린다면 429 를 클라이언트에 내보내고 메시지 큐에 저장한다.
여기서 redis가 휘발성이라 데이터가 날아가버린다면? 영속성 보장을 어떻게 할까?
Redis 데이터 영속성 옵션에 대한 것을 몇가지 제공한다. RDB (데이터 스냅샷 디스크 저장 + 백업유리), AOF (모든 쓰기 연산 로그 파일에 기록), RDB + AOF 로 AOF로 실시간 복구 + RDB 스냅에서 더 큰 장애에 데이터를 복구할 수 있다. (*RDB가 성능이 더 좋음)

이러한 작업을 분산 환경에서 구성한다고 하면 다음 두 조건을 고려해야한다.
- race condition
- synchronization
각 이슈에 대한것은 뒷장에서 조금 더 살펴본다.
다만, 조금만 작성해보면 race condition은 lock을 걸 수 있는데 lock level에 따라 시스템의 성능이 달라진다. 혹은 redis의 정렬 집합을 사용하는것이다. synchronization은 데이터 동기화를 수행해줘야 하는데 이번에는 redis를 공통 db로 사용하는것이다.
마지막으로 챕터 4를 몇 가지 고민해볼만한것들을 소개해주고 있다.
처리율 제한
- hard
- soft
애플리케이션 계층에서 처리율 제한 뿐만 아니라 네트워크 계층에서 iptables를 사용해서 ip주소에 처리율을 적용할 수 있다. (처음에 소개된 내용)
처리율 제한을 회피하는 방법으로 설계를 더 고려해볼만한것
- 클라이언트 측 캐시 사용
- 처리율 임계치 체크
- 예외 및 에러 처리
- 재시도 로직 구현을 하고 이때까지 충분한 백오프 시간을 둔다.
4장 다봤다 !

'IT' 카테고리의 다른 글
| kafka 학습 내용 정리 - 추가중 ... (0) | 2024.02.10 |
|---|---|
| 대규모 시스템 설계 기초 - 5장 (0) | 2024.02.04 |
| 1/21 개발일기 (clustered index, non-clusted index) (0) | 2024.01.21 |
| 1/20 개발일기(thread-poo, resource관리, clustered index) (0) | 2024.01.20 |
| 패션 관련 프로젝트를 진행하며 ... 1 (feat. 500 maker) (3) | 2024.01.14 |