카프카 스터디를 시작하며

카프카 스터디를 시작하게 되었습니다.
데이터가 많이 들어오다 보니 자연스럽게 카프카로 애플리케이션간 데이터를 스트리밍형 ETL을 처리하게 되는것 같습니다.
그래서 시작하게된 스터디... 위 책 내용으로 정리해보면서 잘 몰랐던 개념들을 기록해두려고 합니다.
카프카의 모습
카프카는 어떤 모델인지 알아보면 기존에 시스템들은 Target 애플리케이션과 Source 애플리케이션 사이에 파이프라인이 많이 생기게 되면서 한쪽이 장애가 발생하게 되면 다른 한쪽의 애플리케이션에도 영향을 미칠 수 있게 되었습니다. 그래서 아파치 카프카를 도입하게 됩니다. 아파치 카프카가 일종에 중앙에서 데이터를 처리해주는 역할을 하는것 같습니다. 자료구조의 큐를 살펴보면 First In First Out 자료구조로 동작하게 됩니다.
데이터 포맷
그러다 보니 여러 애플리케이션에서 발생할 수 있는 데이터 포맷이 존재합니다. 직렬화, 역직렬화 모두 가능하기 때문에 데이터 포맷의 문제는 조금(?) 덜 수 있을것 같습니다. 이러한 특 장점 때문에 넷플릭스와 같은 스트리밍형 서비스를 사용하고 있는 회사에서 카프카를 많이 활용하고 있습니다. 자료에 따르면, 36개 이상의 카프카 클러스터를 운영하고 있고 브로커는 약 4,000개가 넘는다고 합니다.
카프카를 오픈 소스로 관리할 수 있는 github이 존재하는데요. https://github.com/apache/kafka 에서 오픈소스 관련 내용을 확인해보실 수 있습니다.
카프카의 역할
여러 애플리케이션에서 데이터를 수집하다 보니 비정형 데이터가 쌓이게 됩니다. 이러한 데이터들이 모이는것을 일종에 데이터 레이크라고 하는데요. 비정형 데이터가 쌓이면 이 데이터를 원하는 형식으로 변경 해주어야 하는데 그 과정을 ETL 이라고 합니다. ETL 을 여러 애플리케이션에 맞게 데이터파이프라인을 구성해주는것은 비효율적이기 때문에 아파치 카프카를 활용하는 방법이 나오게 되었습니다.
카프카의 특징
카프카의 특징은 크게 보면 높은 처리량, 확장성, 영속성, 고가용성을 들 수 있습니다.
높은 처리량
카프카 서버를 담당하는것을 브로커라고 볼 수 있는데 브로커 안에서도 여러 파티션으로 나눠서 데이터를 병렬로 처리할 수 있습니다. 파티션 개수만큼 컨슈머 개수를 늘리게 되면 동일 시간에 여러 데이터를 처리할 수 있게 됩니다.
확장성
카프카 클러스터의 브로커를 운영하고자 할 때 스케일 아웃, 인을 수행할 수 있습니다.
영속성
데이터를 잃어버리지 않고 저장하는 속성을 말하는건데 일반적으로 메모리에 저장하지 않고 파일 시스템에 저장하게 됩니다. 파일에 저장시키기는 하지만 파일 I/O를 고려하게 되면 페이지 캐시 영역에 쓰기 때문에 실질적으로는 메모리를 사용하는것으로 이해하면 될 것 같습니다.
고가용성
클러스터는 카프카 데이터를 Replication을 통해서 고가용성을 확보할 수 있습니다. On-Premise 환경에서 서버 랙, Public Cloud 리전 단위로 데이터를 저장하는 브로커의 옵션을 활용해볼 수 있습니다.
아키텍처
아키텍처는 크게 네 단계의 변천사를 거치게 됩니다.
레거시 데이터 플랫폼 아키텍처 → 람다 아키텍처 → 카파 아키텍처 → 스트리밍 데이터 레이크 아키텍처
레거시 데이터 플랫폼 아키텍처
여러 환경에서 데이터가 수집되는데 ETL 하게 되면 데이터 파편화가 가속됩니다. 이러한 과정은 데이터 거버넌스를 지키기 어려워집니다.

람다 아키텍처
배치, 서빙, 스피드 레이어로 나눠집니다.
배치 레이어의 경우 특정시간 마다 데이터를 일괄 처리하게 됩니다. 서빙 레이어에서는 사용자가 이용할 수 있는 데이터가 저장된 곳을 의미합니다. 그리고 스피드 레이어에서는 원천 데이터를 실시간으로 분석하게 됩니다. 하지만, 이러한 아키텍처에서도 동일 로직이 반복되는 문제가 있습니다. 다소 유연하지 못한 파이프라인이 만들어지게 됩니다.

카파 아키텍처
람다 아키텍처의 문제를 해결하고자 나온 아키텍처 입니다. 배치 레이어를 제거한 스피드 레이어에서 모두 처리할 수 있도록 변경되었습니다.

스트리밍 데이터 레이크 아키텍처
서빙 레이어는 일종에 저장소 개념으로 활용됩니다. 따라서, 카프카로 분석하고 프로세싱한 데이터를 다시 서빙 레이어에 저장할 필요가 없습니다. 이는 운영 리소스를 줄여줄 뿐만 아니라, 필요하다면 Cloud에서 서비스 중인 저장소를 활용할 수 있습니다.
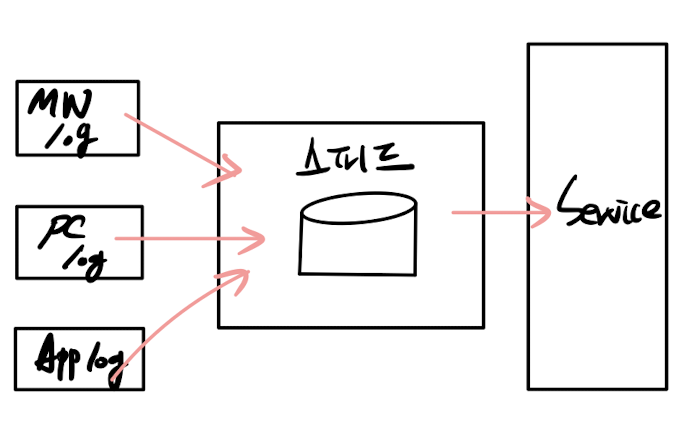
최근 사용중인 아키텍처는 스트리밍 데이터 레이크 아키텍처가 도입되고 있고 이는 결과적으로 스피드 레이어만 참조하여 데이터의 중복, 비정합성 같은 문제를 해결하는데 도움이 되었습니다.
어떻게 아파치 카프카의 서버를 띄울 수 있을까?
실습을 위해서 AWS에 EC2 프리티어로 발급받아 사용하였습니다.
우선 먼저해야할 것은 자바를 설치해야 합니다. 실습 과정에서는 1.8 버전을 사용합니다.
$ sudo yum install -y java-1.8.0-openjdk-devel.x86_64
$ java -version그리고, 카프카 브로커를 실행하기 위해서 카프카 바이너리 패키지를 다운로드 받습니다.
받은 카프카 바이너리 패키지는 압축을 풀어 줍니다.
$ wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz카프카 브로커 실행 옵션을 지정해줘야 하는데 server.properties에서 설정해줄 수 있습니다.
$ vi config/server.propertiesserver.properties 영역에서 아래 영역의 주석을 해제하고 EC2의 공개 IP를 your.host.name 을 지우고 이 영역에 대체합니다.
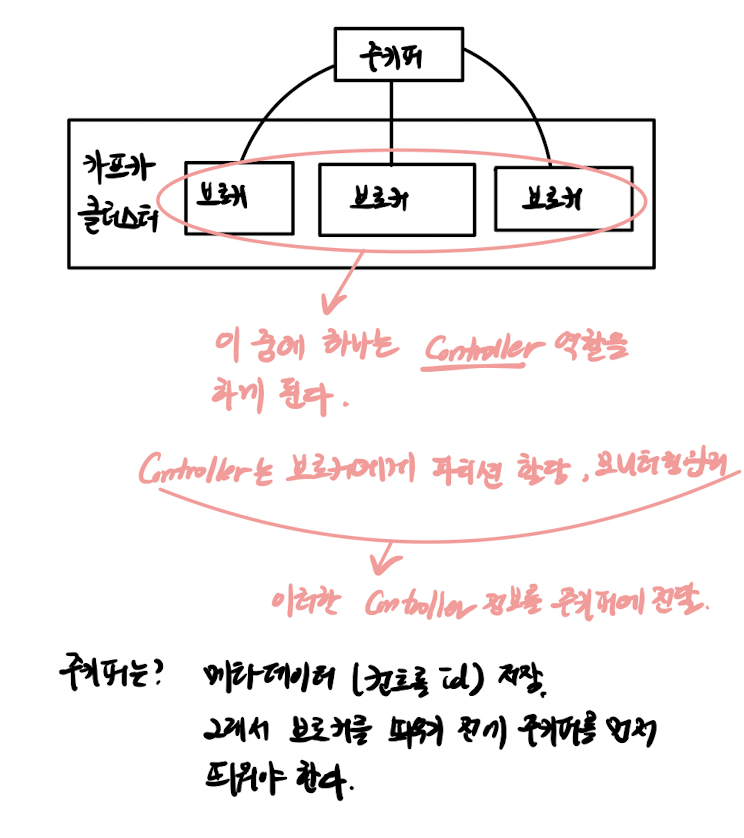
advertised.listeners=PLAINTEXT://your.host.name:9092주키퍼는 카프카의 클러스터 컨트롤러 정보를 가지고 있는데 메타 데이터를 저장한다고 생각하면 좋을것 같습니다. (아래 그림 참고)
카프카 서버를 띄우기 위해서는 주키퍼를 우선적으로 띄워야 합니다. jps로 JVM 프로세스 상태를 확인합니다.
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
$ jps -vm주키퍼를 띄웠으면 카프카 브로커를 실행해 봅니다. 이때 카프카 브로커를 띄웠을 때 실행 로그도 같이 확인할 수 있습니다.
$ bin/kafka-server-start.sh -daemon config/server.properties
$ jps -m
$ tail -f logs/server.log
QnA
스터디를 진행하면 질문 하나씩 필수적으로 하도록 만들었습니다.
주키퍼를 왜 써야 하는지? 주키퍼는 어떤 역할을 수행하게 되는지 궁금합니다.
주키퍼의 역할은 기본적으로 카프카의 메타데이터 정보를 저장하게 되는데, 카프카의 상태관리를 수행하기도 합니다. 분산 애플리케이션을 안정적인 서비스로 운영하기 위해서 중앙에서 집중적으로 관리하고 네이밍, 동기화 서비스를 지원합니다. 카프카 서버들이 클러스터를 구성하고 분산 애플리케이션들이 클라이언트가 되서 주키퍼 서버와 커넥션을 갖게 되면 상태 정보를 주고 받게 됩니다. 이와 같은 경우 Server는 주키퍼, Client는 카프카가 됩니다. 주키퍼를 꼭 써야 하는 이유는 브로커 서버들이 클러스터를 구성하게 될텐데 브로커 중 하나가 Controller 역할을 하게 됩니다. 이러한 컨트롤러 정보, 즉 메타 정보를 주키퍼가 가지고 있기 때문에 브로커를 띄우기 전에 주키퍼를 우선적으로 띄워야 합니다.
정리
카프카 챕터1, 2 중간 내용을 정리해보았는데요. 아직 첫 스터디라 어떻게 정리하면 좋을지 어디까지 내용을 노출해야 할지 감을 잘 못잡는것 같습니다. 카프카 전체적인 모델에 대해 이해할 수 있었고 조금 더 나아가 카프카 브로커를 어떻게 띄우고 실행은 어떤식으로 하는지 이해할 수 있었습니다. 조금 더 공부해서 카프카를 이용한 토이 프로젝트를 진행해보고 싶네요.
'IT' 카테고리의 다른 글
| 캐시방법 (0) | 2023.03.11 |
|---|---|
| Spring Bean (0) | 2023.02.04 |
| 넥스트스텝 - 레이싱 카 2단계 (0) | 2022.01.30 |
| 넥스트스텝 - 레이싱 카 1단계 (0) | 2022.01.29 |
| 넥스트스텝 - 계산기 리뷰 (2) | 2022.01.29 |