AWS redShift 실습하기
시작
아마존 웹 서비스에 로그인합니다. 로그인하고 왼쪽 패널을 확인합니다.
아래 링크를 그대로 수행한 것입니다.
https://docs.aws.amazon.com/ko_kr/redshift/latest/gsg/rs-gsg-prereq.html
스크린샷으로 남겨 둬서 나중에 헤매지 않기 위해서 포스팅합니다.
IAM 역할 생성
IAM 쪽으로 이동해서 역할을 클릭합니다.
redShift 시작하기전에 IAM를 통해 Identity를 확인하기 위함인듯 합니다.

역할 만들기를 보면 AWS 서비스 부분이 있습니다. 이것을 클릭하고,
밑에 보면 확인할 수 있는 Redshift를 클릭합니다.
그리고 스크롤을 내려서 보면 사용 사례 선택 부분이 있습니다.
여기서 Redshift - Customizable을 클릭합니다.
역할 만들기를 확인할 수 있습니다. 역할은 AmazonS3Read를 선택해 줍니다.
태그 추가는 Skip 합니다.
역할 이름을 지정하고 역할 만들기를 클릭합니다.
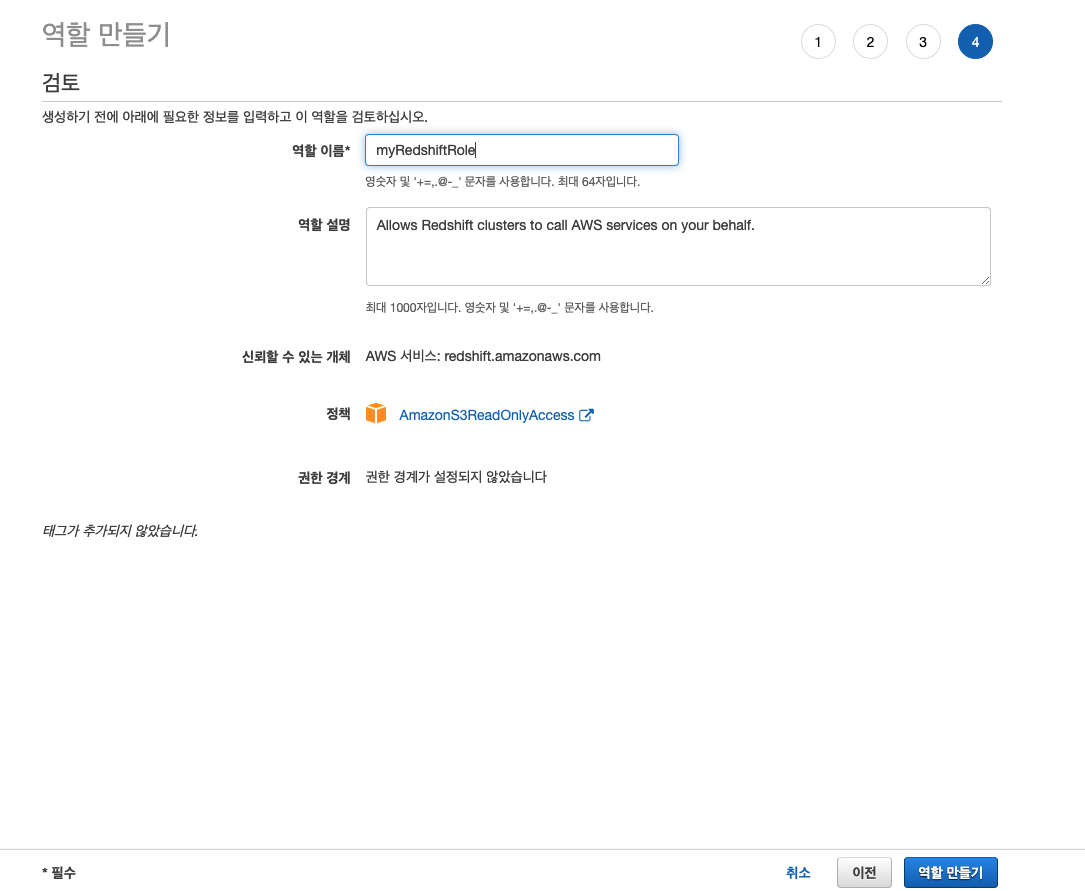
역할이 생성된 후 ARN을 복사해 둡니다. 나중에 S3에 데이터를 로딩할 때 사용하게 됩니다.
참고로 ARN 은 일회성이기 때문에 해당 포스팅 작성 이후 접근권한은 해제 됩니다.
클러스터 생성
region을 우선 선택해 줍니다. 가장 가까운 한국리전으로 선택합니다. (서울)

클러스터 생성을 합니다.
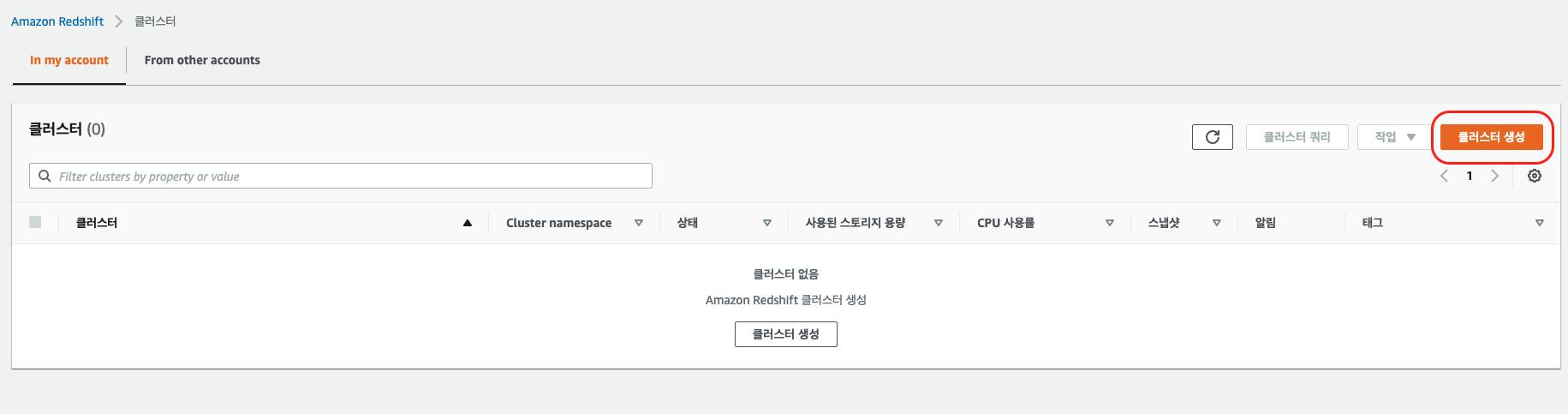
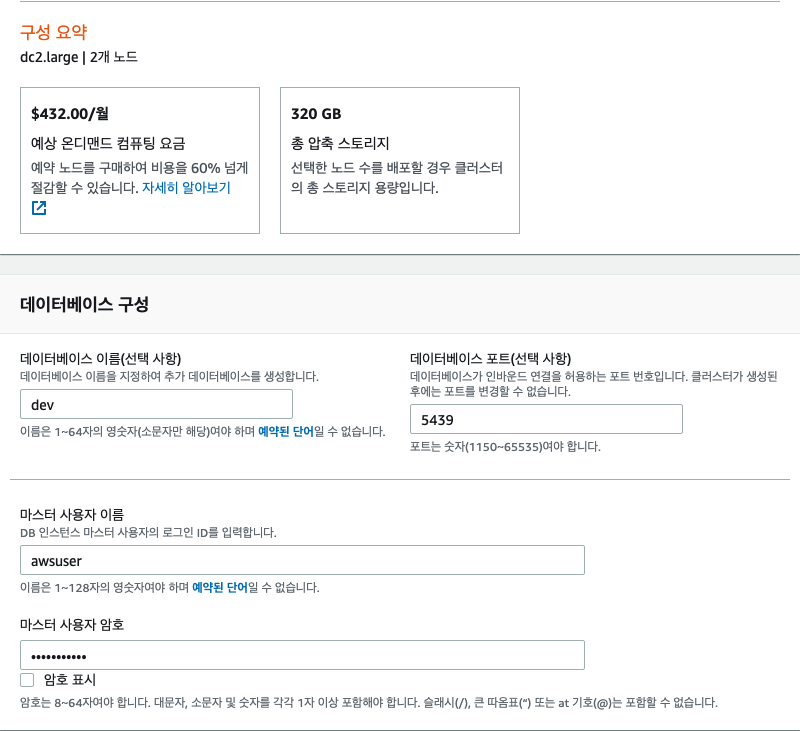
클러스터 생성 시 여러 옵션이 있는데 아래 사진 처럼 구성하였습니다.
클러스터 식별자는 식별 가능한 이름이어야 합니다.
테스트 용도는 무료 평가판을 사용해도 되는데, 프로덕션을 선택한 이유는 여러 옵션을 설정해 주고 싶어서..
노드 유형과 노드는 AWS에서 권장하는 크기만큼 지정하였습니다.
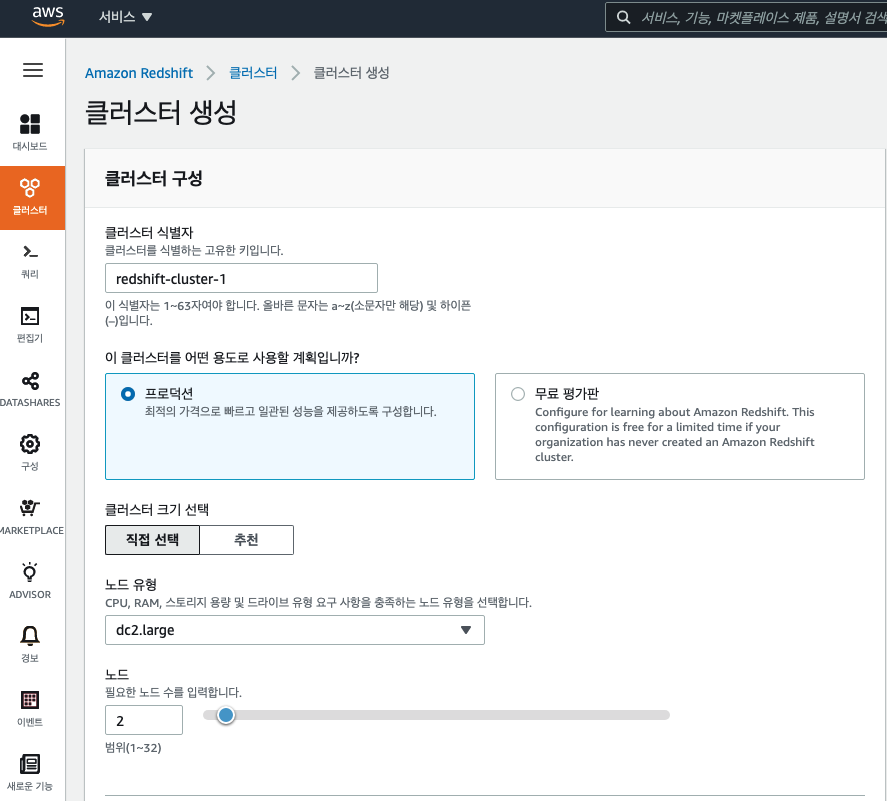
마스터 사용자 이름은 보통 awsuser 로 사용하는 듯 합니다.
비밀번호는 숫자, 소문자, 대문자, 특수문자 조합으로 들어가야 합니다. 최소 길이가 8 입니다.
데이터베이스 이름과 포트도 가이드라인대로 구성하였습니다.
클러스터를 생성합니다.
클러스터 생성 중...
생성!

myReadshiftRole IAM을 클러스터에 추가해 줍니다.

추가 안하면 아래처럼 에러 납니다.
error: The requested role arn:aws:iam::911541272721:role/myRedshiftRole is not associated to cluster code: 30000 context: query: 1489 location: xen_aws_credentials_mgr.cpp:361

클러스터 액세스 허가, 쿼리 편집기에 대한 액세스 권한 부여
Amazon Redshift 클러스터에서 호스팅하는 데이터베이스에 대한 쿼리를 쉽게 실행할 수 있습니다.
클러스터 생성 후에 Amazon Redshift 콘솔을 사용하여 즉시 쿼리를 실행할 수 있습니다.
Amazon Redshift 쿼리 편집기에 액세스하려면 권한이 있어야 하는데
AmazonRedshiftQueryEditor
AmazonRedshiftReadOnlyAccessIAM
정책을 클러스터에 액세스 하는 데 사용하는 IAM 사용자와 연결합니다.
AWS IAM에서 사용자로 이동합니다.
사용자에 접속하게 되면 사용자가 없으므로 만들어 주는 작업을 우선 하였습니다.
사용자 이름은 무시해주세요.
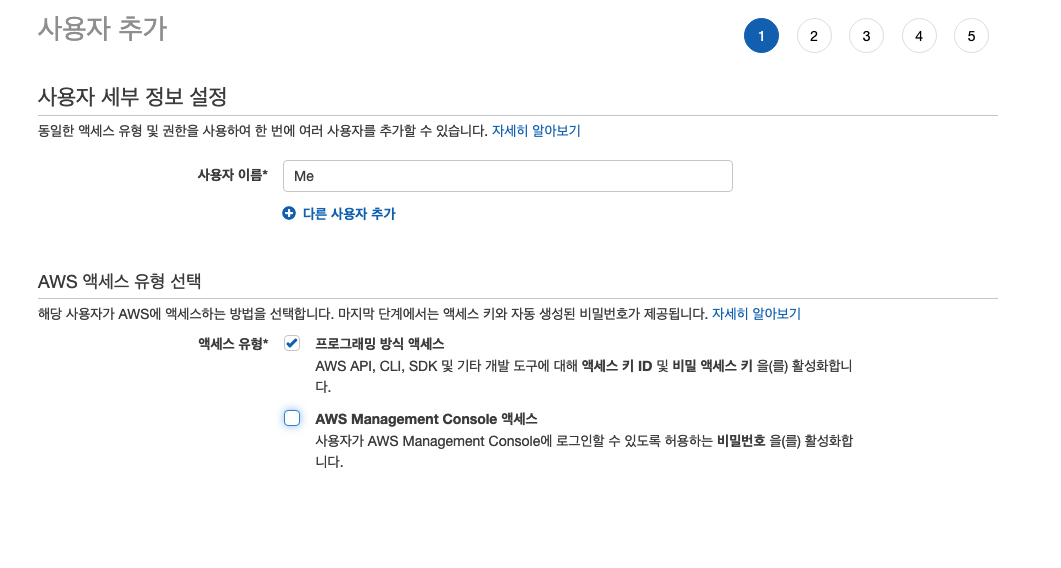
그룹을 사용하지 않기 때문에 사용자를 추가하진 않고 redshift에 접근할 수 있는 정책을 바로 사용자와 연결합니다.
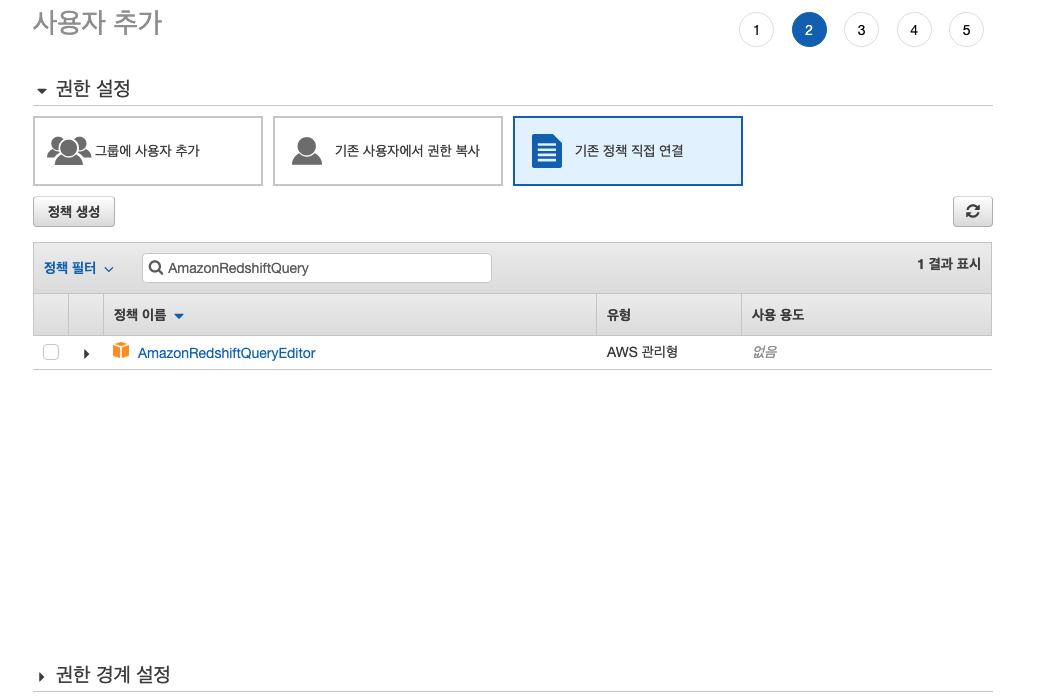
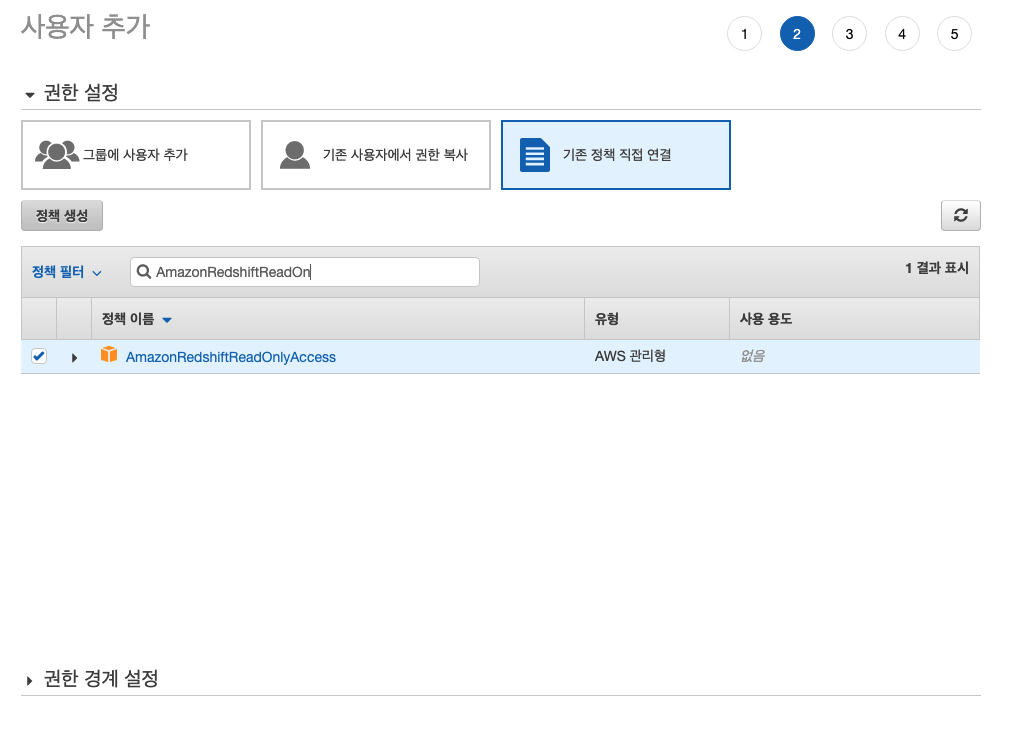
권한 2개를 추가해 줍니다.
태그 항목을 Skip 합니다.
사용자 추가가 완료되었습니다.
사용자와 연결된 정책에 잘못된 점이 없는지 확인하고 사용자를 만듭니다.
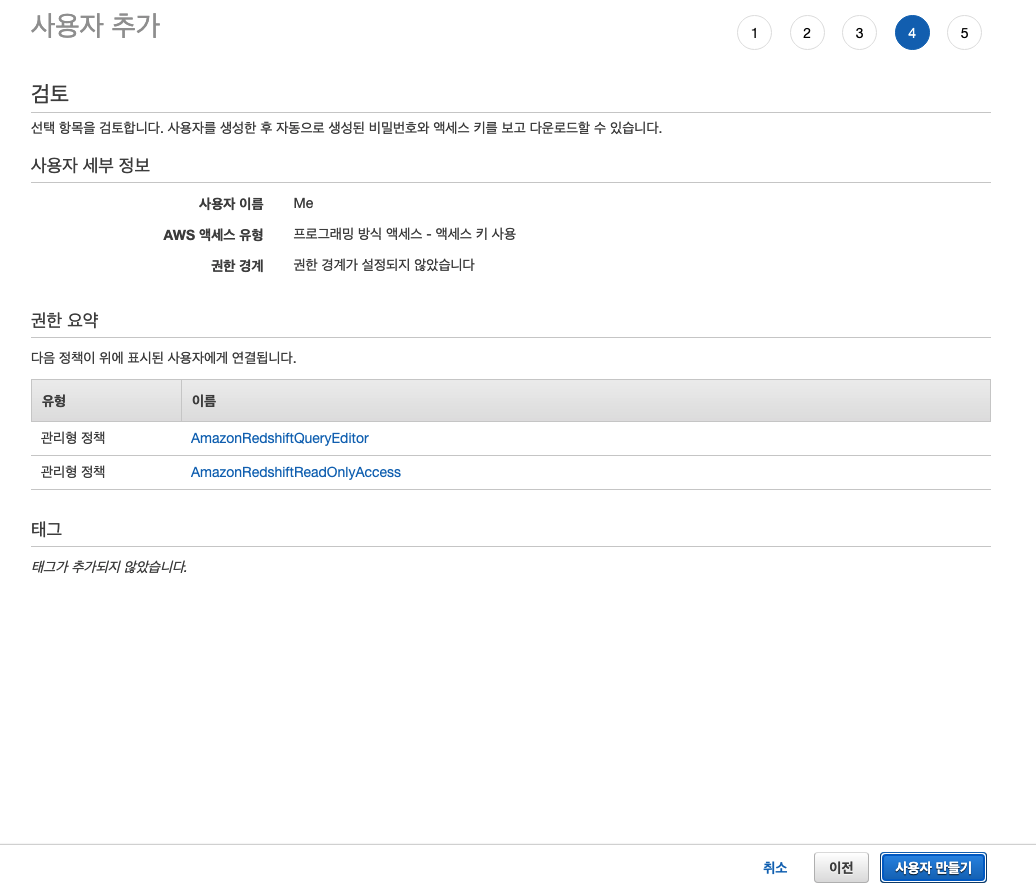
redshift 메뉴로 넘어와서 편집기를 클릭합니다.
편집기 부분에 데이터베이스 연결 버튼이 있습니다.
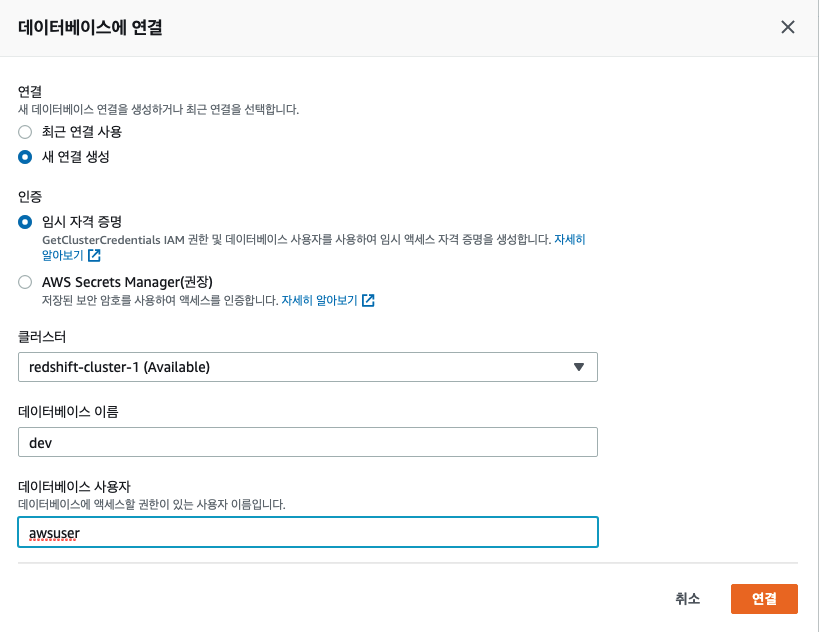
데이터베이스 연결 시 기존에 만들어 주었던 클러스터와 데이터베이스 이름(dev), 사용자(awsuser)를 등록해 주었습니다.
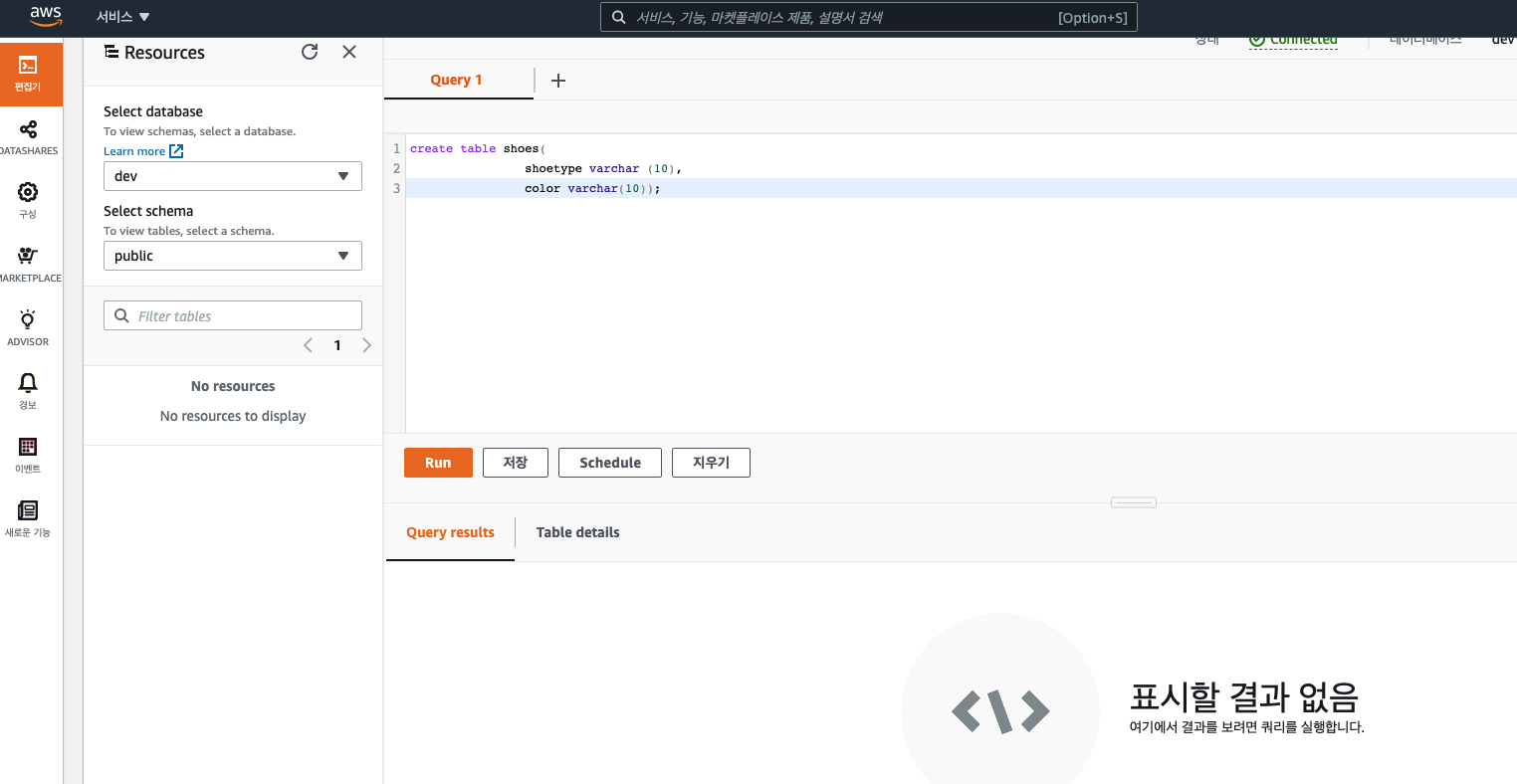
해당 쿼리를 작성하여 실행해보았습니다.

코드1
|
1
2
3
|
create table shoes(
shoetype varchar (10),
color varchar(10));
|
cs |

마찬가지로 insert문을 수행해 보겠습니다.

코드2
|
1
2
3
|
insert into shoes values
('loafers', 'brown'),
('sandals', 'black');
|
cs |


코드3
|
1
|
select * from shoes;
|
cs |
결과 값이 잘 나오는것을 확인할 수 있습니다.
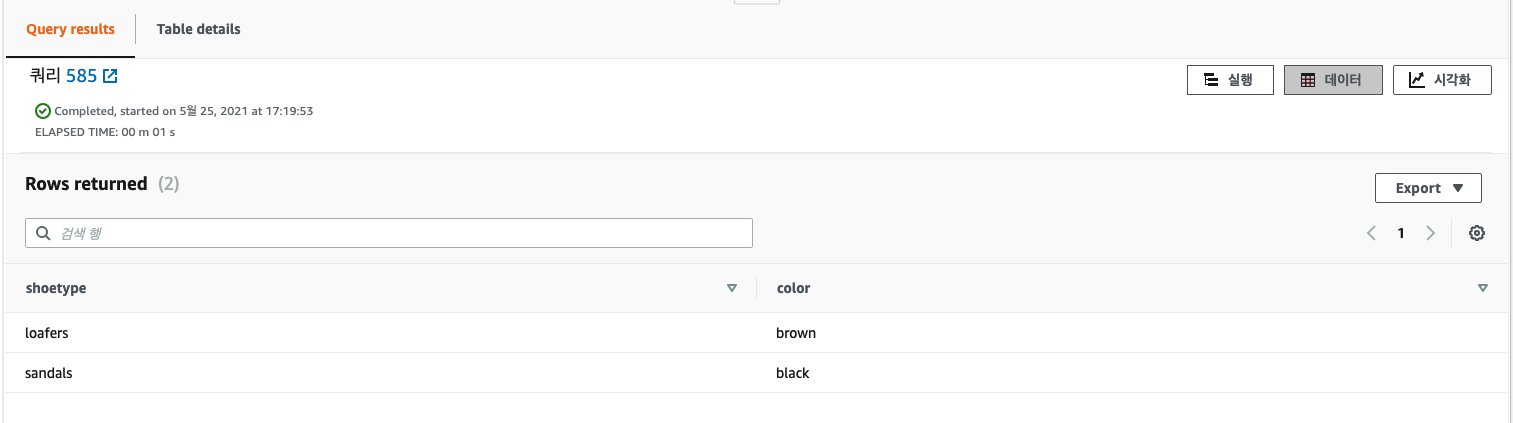
S3와 연동해서 샘플 데이터를 로드해서 쿼리로 조회
아래 쿼리를 실행합니다.
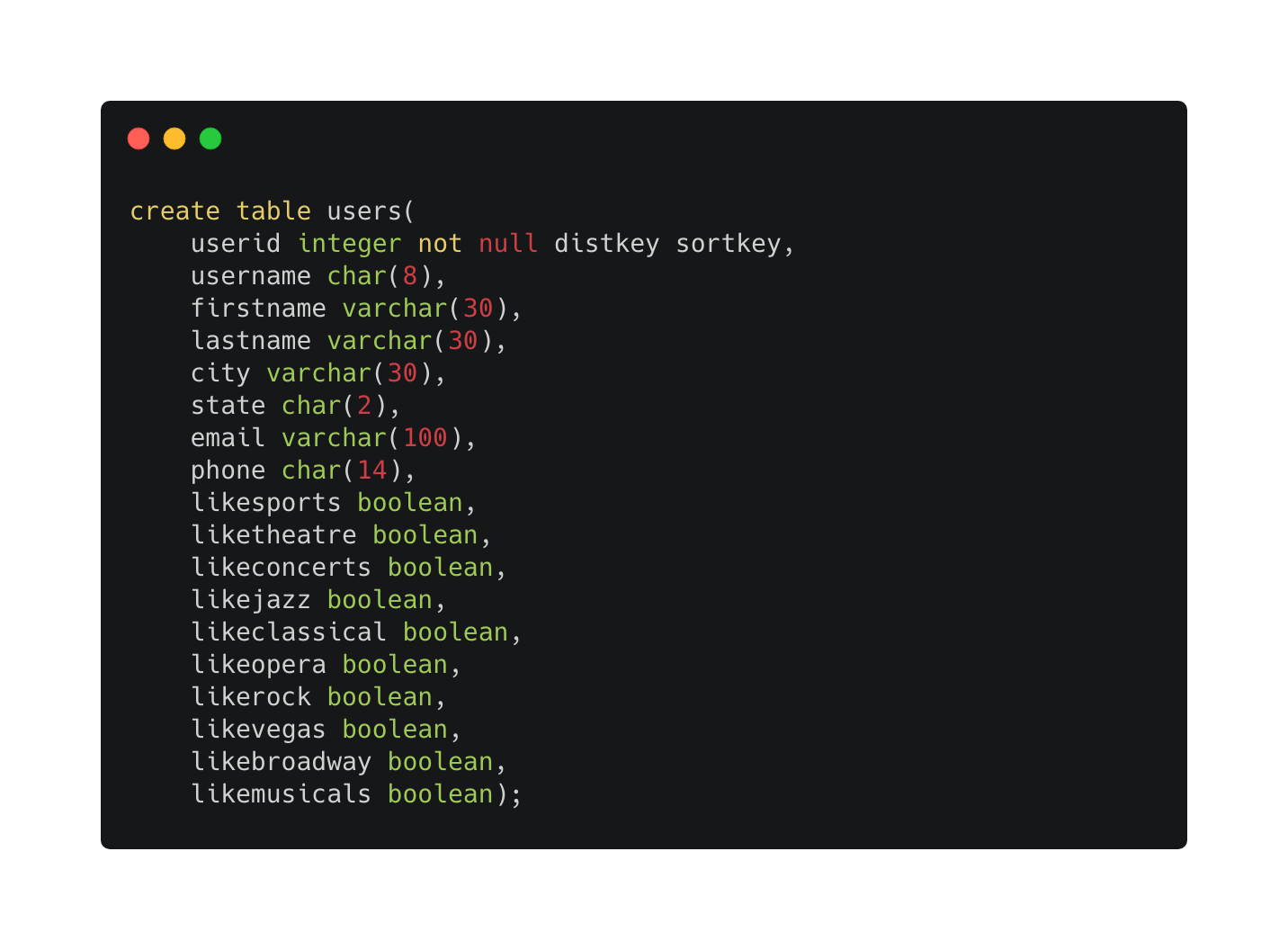
코드4
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
create table users(
userid integer not null distkey sortkey,
username char(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state char(2),
email varchar(100),
phone char(14),
likesports boolean,
liketheatre boolean,
likeconcerts boolean,
likejazz boolean,
likeclassical boolean,
likeopera boolean,
likerock boolean,
likevegas boolean,
likebroadway boolean,
likemusicals boolean);
|
cs |
넣다보니 다 넣게 되었다..
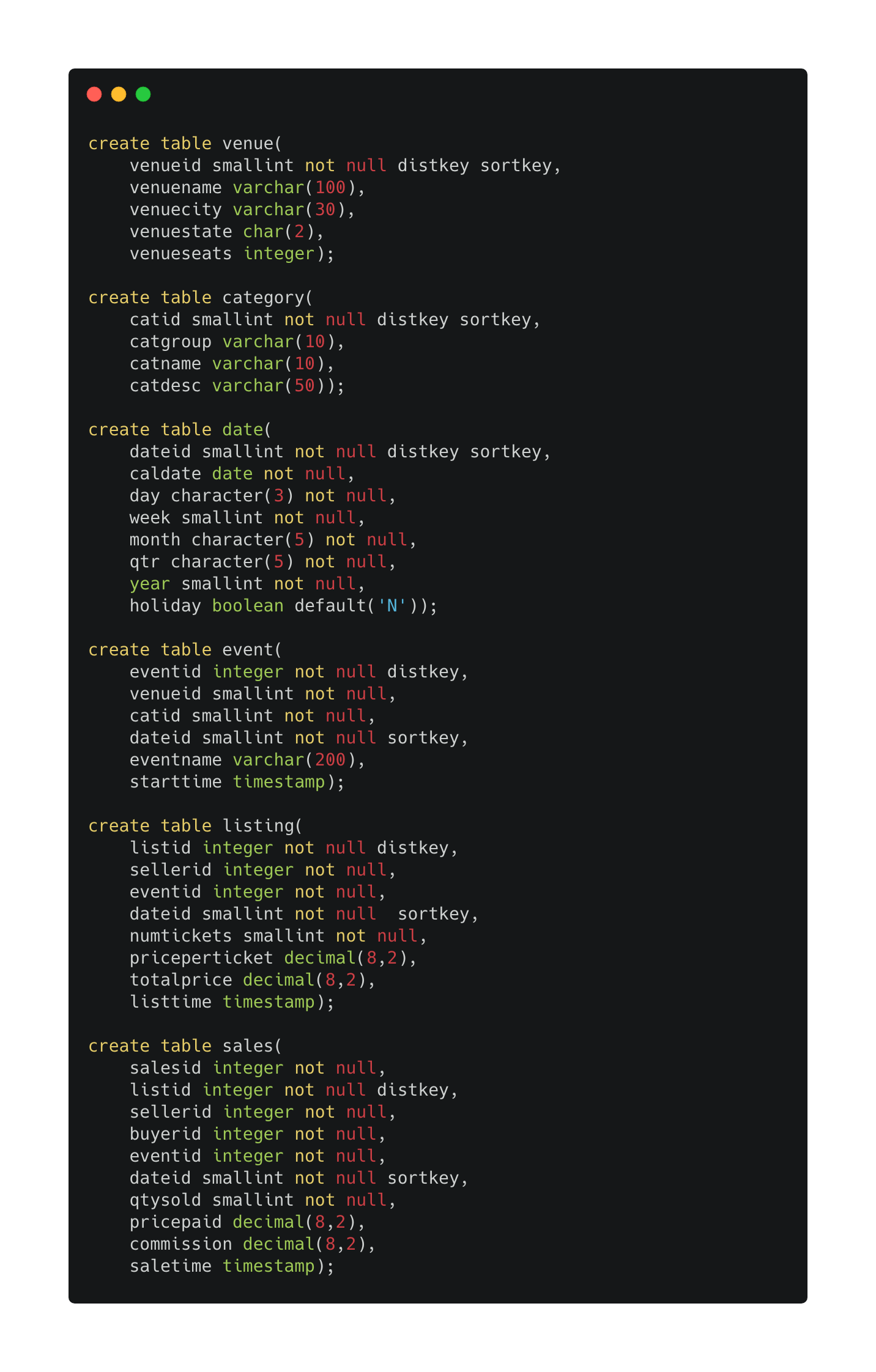
코드5
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
create table venue(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer);
create table category(
catid smallint not null distkey sortkey,
catgroup varchar(10),
catname varchar(10),
catdesc varchar(50));
create table date(
dateid smallint not null distkey sortkey,
caldate date not null,
day character(3) not null,
week smallint not null,
month character(5) not null,
qtr character(5) not null,
year smallint not null,
holiday boolean default('N'));
create table event(
eventid integer not null distkey,
venueid smallint not null,
catid smallint not null,
dateid smallint not null sortkey,
eventname varchar(200),
starttime timestamp);
create table listing(
listid integer not null distkey,
sellerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
numtickets smallint not null,
priceperticket decimal(8,2),
totalprice decimal(8,2),
listtime timestamp);
create table sales(
salesid integer not null,
listid integer not null distkey,
sellerid integer not null,
buyerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
qtysold smallint not null,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp);
|
cs |
아무튼 실행한 쿼리가 전부 잘 작동하는것을 확인할 수 있었습니다.
이번엔 버킷을 생성해보겠습니다. 버킷의 생성 목적은 파일을 올려서 redShift 로 쿼리를 조회하는 목적으로 사용됩니다.
중간에 이전에 생성한 IAM 역할을 사용할 것입니다. (ARN) 이 작업은 뒤에서 하게 됩니다.
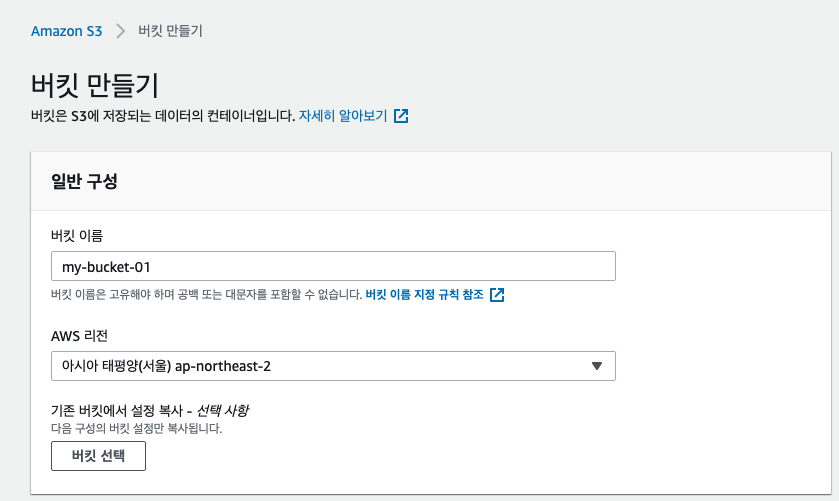
https://docs.aws.amazon.com/ko_kr/redshift/latest/gsg/samples/tickitdb.zip 에서 파일을 다운받아서 S3에 업로드 하였습니다.
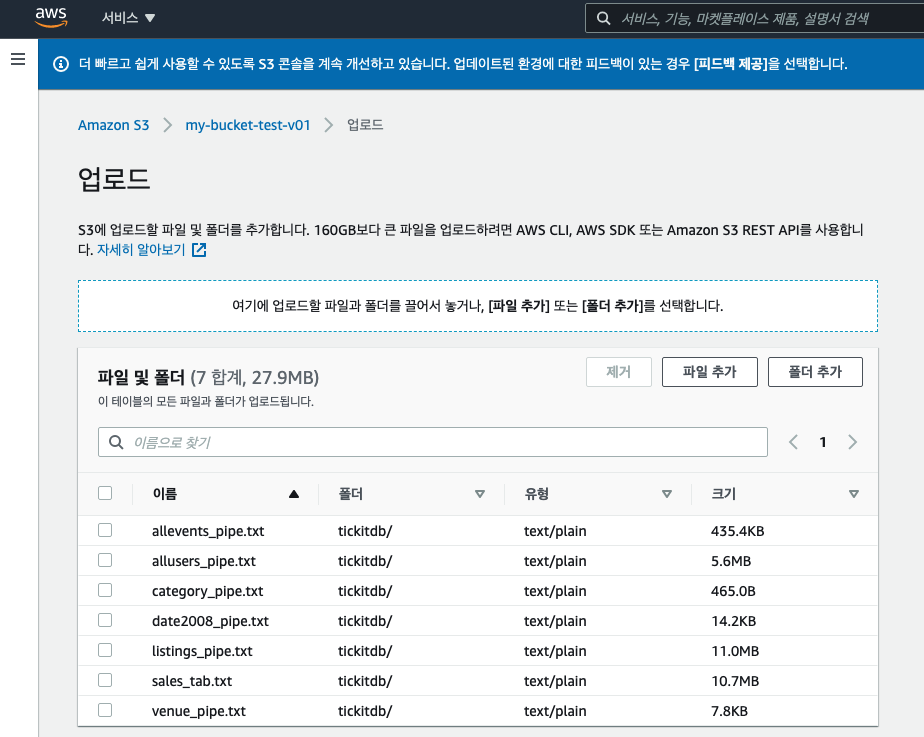
redshift cluster 의 쿼리 편집기로 넘어와서 아래 명령어를 수행합니다.
S3에 있는 데이터를 로드해와서 redshift 로 query를 수행하게 됩니다.
앞서, 만들어둔 샘플 데이터 테이블 각각에 대해 모두 로드 작업을 수행하게 됩니다.

코드6
|
1
2
3
|
copy users from 's3://<myBucket>/tickit/allusers_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
|
cs |
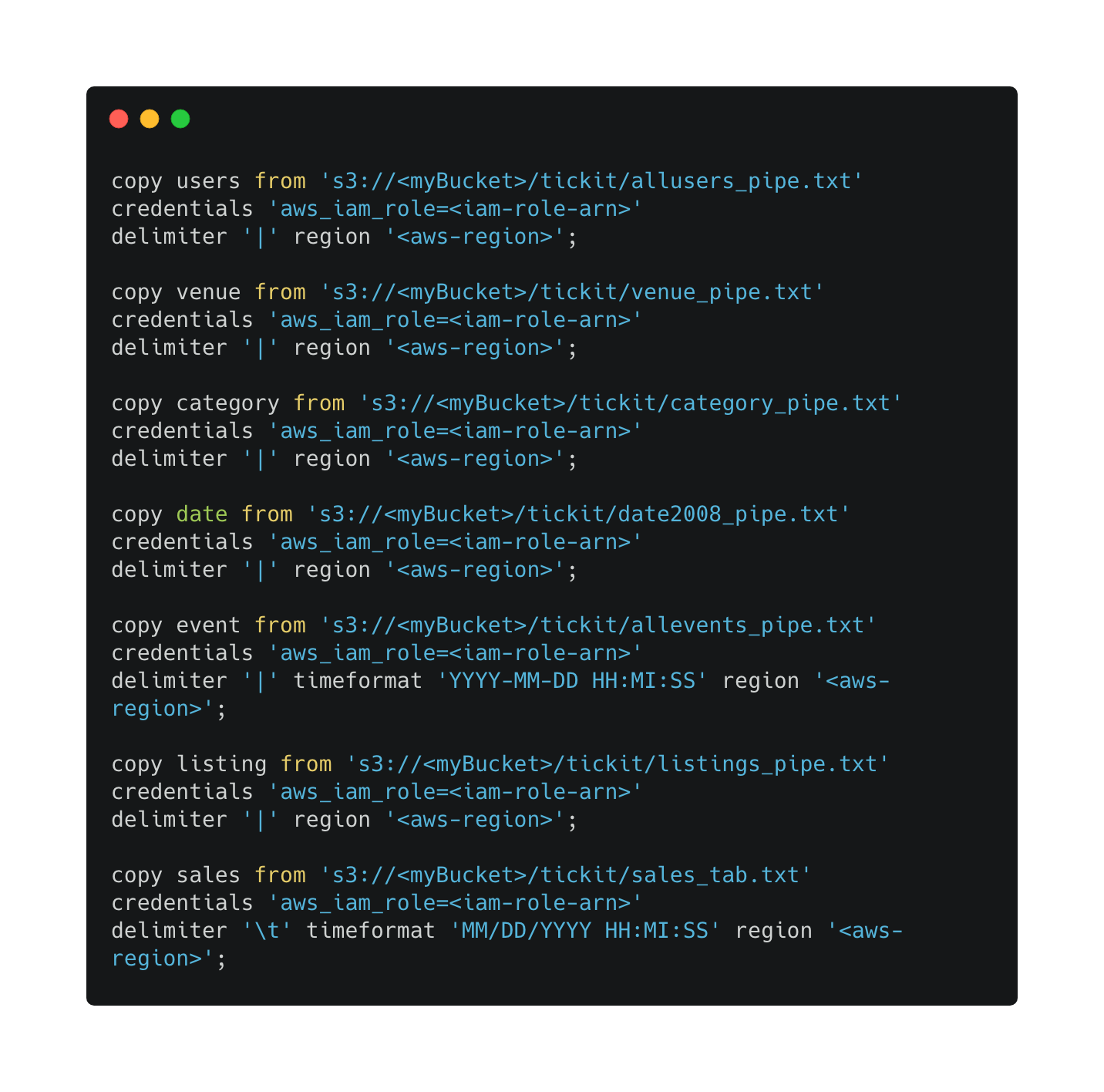
코드7
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
copy users from 's3://<myBucket>/tickit/allusers_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
copy venue from 's3://<myBucket>/tickit/venue_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
copy category from 's3://<myBucket>/tickit/category_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
copy date from 's3://<myBucket>/tickit/date2008_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
copy event from 's3://<myBucket>/tickit/allevents_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS' region '<aws-region>';
copy listing from 's3://<myBucket>/tickit/listings_pipe.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '|' region '<aws-region>';
copy sales from 's3://<myBucket>/tickit/sales_tab.txt'
credentials 'aws_iam_role=<iam-role-arn>'
delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS' region '<aws-region>';
|
cs |
S3에 올라간 샘플 데이터를 redshift로 모두 로딩 완료된 후 아래 쿼리 작업을 수행합니다.
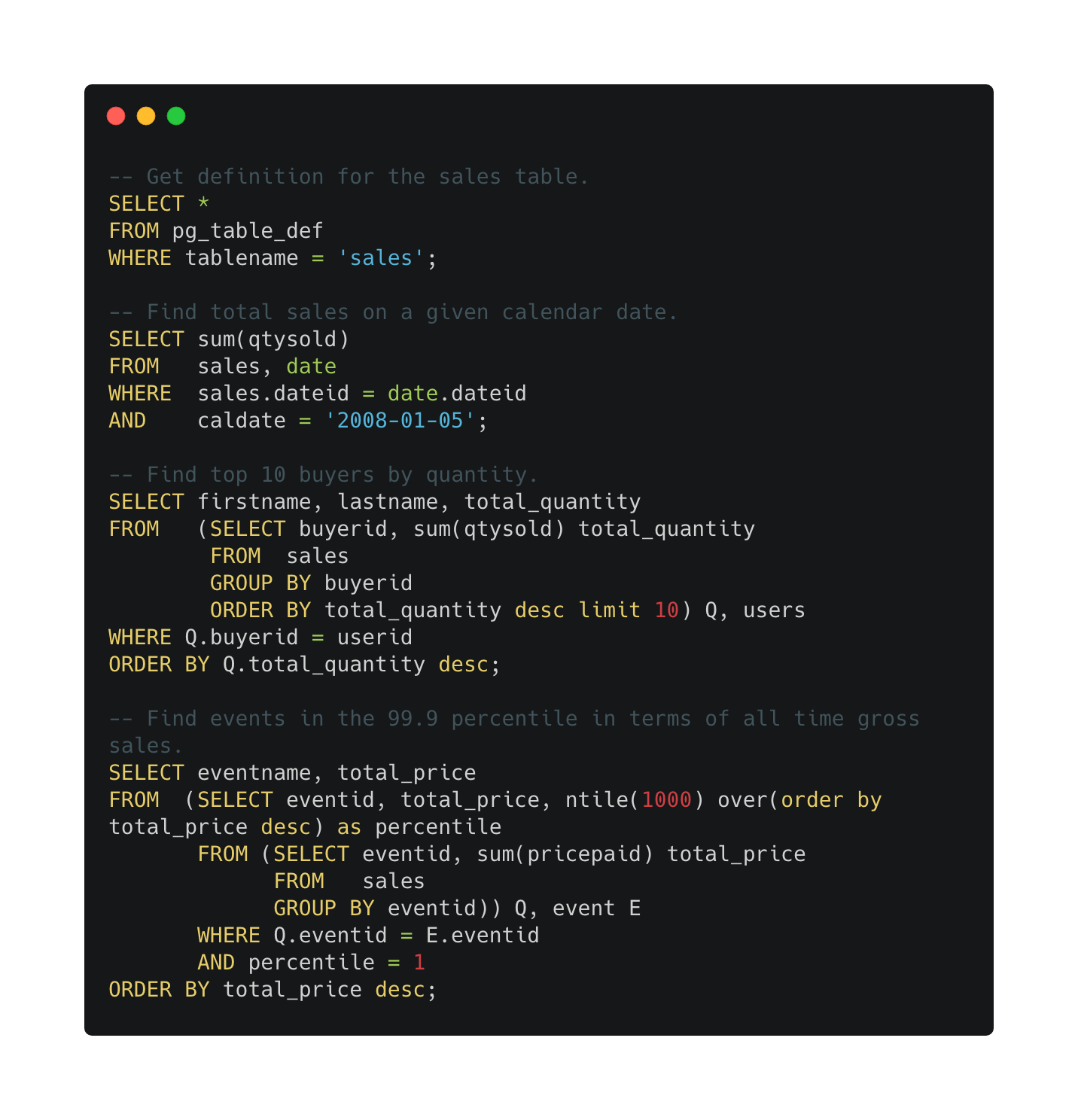
코드8
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
-- Get definition for the sales table.
SELECT *
FROM pg_table_def
WHERE tablename = 'sales';
-- Find total sales on a given calendar date.
SELECT sum(qtysold)
FROM sales, date
WHERE sales.dateid = date.dateid
AND caldate = '2008-01-05';
-- Find top 10 buyers by quantity.
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales
GROUP BY buyerid
ORDER BY total_quantity desc limit 10) Q, users
WHERE Q.buyerid = userid
ORDER BY Q.total_quantity desc;
-- Find events in the 99.9 percentile in terms of all time gross sales.
SELECT eventname, total_price
FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) Q, event E
WHERE Q.eventid = E.eventid
AND percentile = 1
ORDER BY total_price desc;
|
cs |
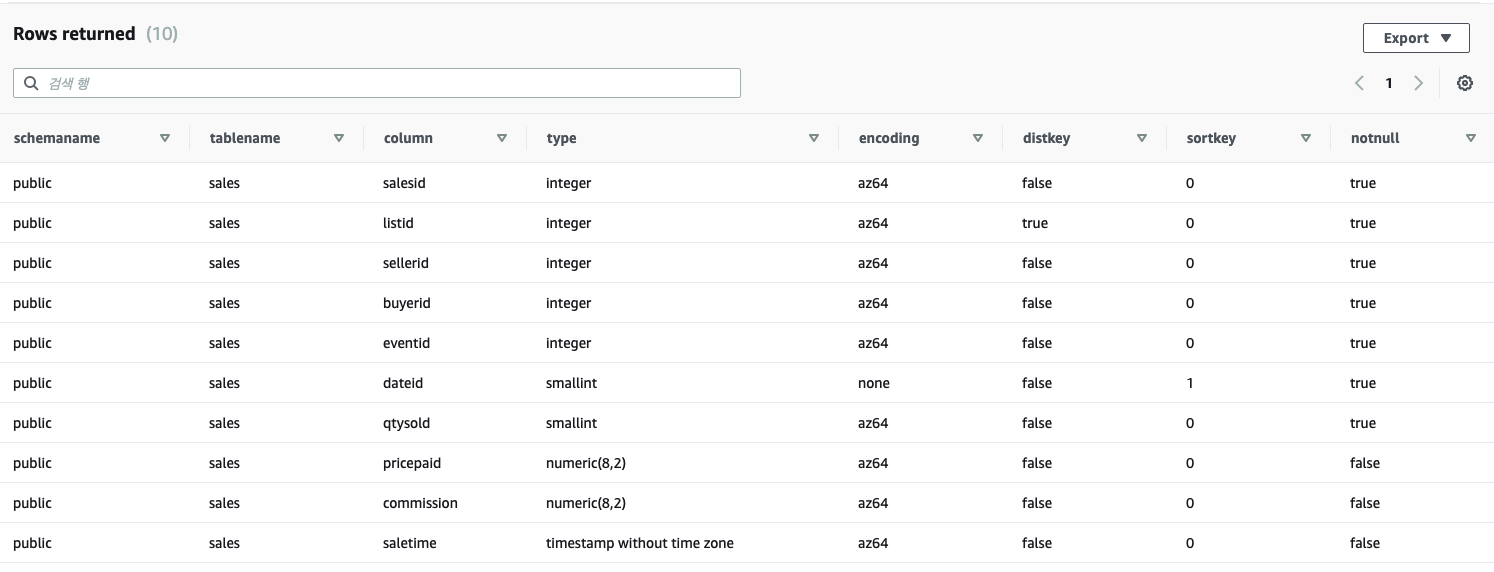
위 쿼리 수행 시 결과 입니다.
'AWS' 카테고리의 다른 글
| AWS01 :: AWS - 공유 인스턴스(Shared Tenancy) (0) | 2020.06.04 |
|---|
댓글을 사용할 수 없습니다.